Best Practices
Every organization can establish a solid disaster recovery foundation when they follow a universal set of best practices for DR planning. This becomes a way to reevaluate the plan, strategy, and testing to ensure that they constantly meet the needs of the organization. A good list of best practices includes:
- Continuously iterate the process to keep up with business and IT changes by performing regular IT infrastructure and application mapping.
- Maintain a readily accessible disaster recovery playbook so everyone knows their roles and what procedures will take place based on specific triggers. A DR plan must also be easily modifiable since it is subject to change with every iteration.
- Create a plan for backup work locations with secure system-access procedures for a hybrid workforce.
- Schedule DR plan testing each quarter at a minimum, with large enterprises performing monthly testing. The IT infrastructure and application mapping should always precede the test to have an updated view of all assets and dependencies.
- Develop comprehensive test reports that provide insights into the success and/or errors of each test as well as the test procedures.
- Institute regular employee training and drills for the organization to be certain everyone knows the processes and procedures in the event of any disaster.
- Integrate and/or coordinate DR planning with existing security and data protection solutions and processes.
Meet Faddom
Business continuity and disaster recovery (BCDR) should be part of a holistic approach to making sure every organization can remain operational regardless of the form of downtime or disaster. By implementing BCDR planning, organizations can align business functions to IT dependencies to reduce risk and ensure resilience, uptime, and profitability.
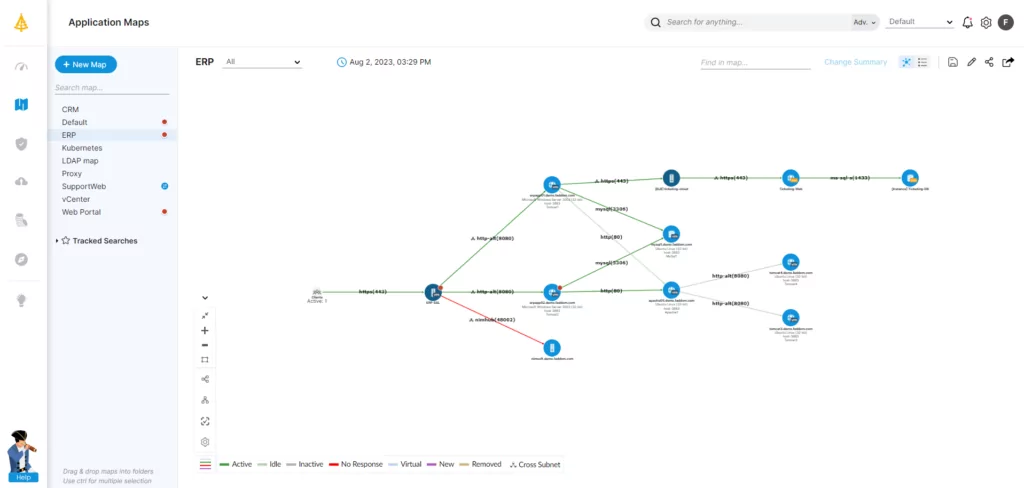
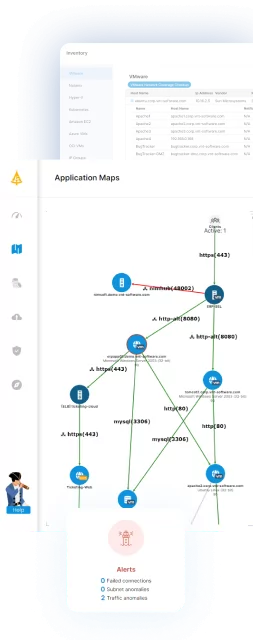
IT Infrastructure, devices, systems, applications, workloads, databases, and all dependencies are at the heart of business productivity, second only to an organization’s people. Having a comprehensive and constantly updated map of these assets is critical to developing a resilient and agile disaster recovery plan and strategy.
Every successful DR plan relies on visibility into the IT infrastructure, application, and services environment across on-premises, the cloud, and beyond the network edge. A comprehensive, automated mapping and discovery solution is the starting point for achieving an accurate view of ongoing environmental changes and an effective BCDR strategy.
Start a free trial today to see how Faddom helps organizations ensure comprehensive and proactive DR/BC through fast, secure, and comprehensive asset and dependency mapping.