When thinking about cloud infrastructure, I often worry about data security, complexity, and costs. Our on-premises and data center infrastructure has far more predictable usage costs, and the topology is much easier to manage. But that doesn’t mean that the cloud doesn’t offer us certain advantages.
For example, cloud infrastructure enables offsite disaster recovery, giving us geographically distributed and protected backups. Does your company have a disaster recovery strategy and plan in place? Has it been tested? If you’re backing your servers up to the same location and not using a cloud platform, you can’t use disaster recovery software effectively at all. (For more information, see our Guide to Disaster Recovery.)
Why Have Disaster Recovery?
I look at disaster recovery (DR) as a tool to achieve one key objective: business continuity. When I evaluate DR plans and solutions, I’m always thinking in the context of business continuity, always asking “how will this let us maintain business operations in the event of a disaster or outage?”
Perform a quick mental evaluation of your DR strategy right now. What would happen if your primary production workloads go down? How long would it take to restore functionality? Minutes? Hours? What if the physical location is compromised by a natural disaster like a flood or a fire? A potential nightmare scenario is some kind of hack or breach, in which case you can no longer trust any of your infrastructure and need to start over from scratch.
Organizations often don’t consider these types of scenarios—nor how to remediate them—until it’s far too late. In the context of business continuity, having an effective DR plan in place can mean the difference between survival and failure.
How to Get Started
Identifying DR as being critical to the survival of your business is step one. The next step is to plan and implement an actual DR strategy.
I like to start by identifying key risks to the business. A good high-level list includes:
- Hack or compromise
- Weather or “act of God”
- Transit provider outage (Internet backbone)
- General data loss or corruption
This list is by no means comprehensive, or excessively detailed, but that’s not the point. The goal is to start thinking about some example scenarios and to start planning a strategy and operational procedure to deal with them.
Once the high-level risks have been identified, the next step is to catalog the assets and data that are critical to your business continuity. Anything running a production workload, or that contains customer data, is an absolute necessity in a DR plan. What often gets overlooked is the secondary and tertiary dependencies. Need access to tools or documentation for restarting your core application correctly? That should also be included.
Disaster Recovery Software and Tools
I won’t be able to tell you how to pick the perfect disaster recovery solution for backing up and recovering servers — there’s just too much nuance and unique technical detail in each environment. What I can do is help provide a baseline and some basic criteria for choosing a tool.
Let’s start by looking at some of the well-known solutions available today.
Disaster Recovery Planning and Infrastructure Visibility
Before you can back up and recover anything, you need to know what you have and how it fits together. The tools in this category build that picture.
1. Faddom
![]()
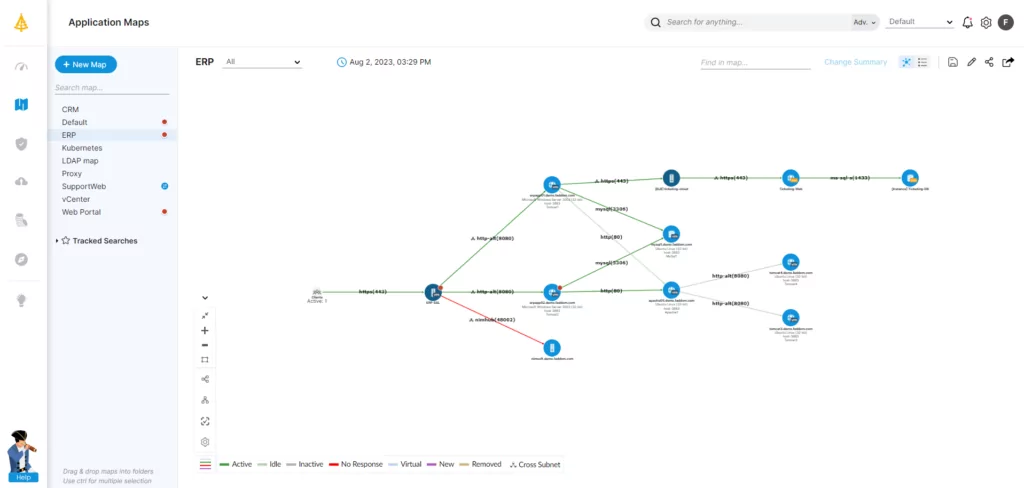
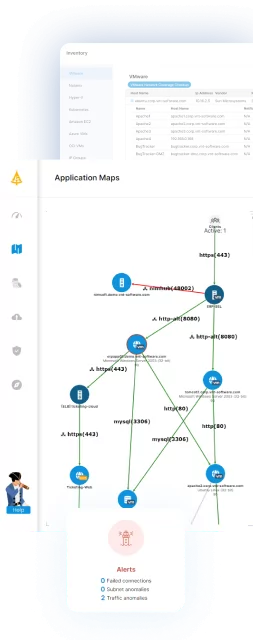
Faddom is an application dependency mapping platform built to support disaster recovery and business continuity planning. It maps an organization’s entire hybrid IT environment — both on-premises and in the cloud — along with its business applications, often in as little as 60 minutes. The platform is agentless and credential-less, running passively from network traffic without requiring firewall changes. It produces an up-to-date asset inventory and shows how servers and applications connect to one another, which teams use to decide what to back up and in what order. Because it maps continuously, the picture stays current as the environment changes, rather than relying on a one-time snapshot.

Key features include:
- Hybrid environment mapping: Maps on-premises servers, cloud instances, applications, and their dependencies in roughly an hour, building the asset inventory that any backup or recovery plan depends on. The map covers both the live production environment and the backup environment, so teams have a single view of what needs to be protected.
- Dependency and impact analysis: Surfaces upstream and downstream relationships between servers and applications so teams can see what depends on what. This helps identify the secondary and tertiary dependencies that are easy to miss and lets teams analyze how a given server affects both the live site and the backup site.
- Backup prioritization support: Lets teams weigh the relative importance of each system and its dependencies, which informs the order in which systems should be backed up and brought back online. This is used to build DR playbooks around the correct recovery sequence rather than guesswork.
- Agentless, passive data collection: Discovers the environment without installing agents, using credentials, or changing firewall rules, working passively from network traffic on an IP basis. It can also operate offline, which reduces the operational impact of running discovery against production systems.
- Continuous, real-time maps: Maps the environment around the clock and keeps the visualization current as assets change. This keeps the dependency data aligned with the environment a DR plan is meant to protect, instead of going stale between manual reviews.
- Separation of backup and live sites: Lets teams confirm that no unintended dependencies exist between the backup and production environments, which helps verify that a failover site can operate independently of the systems it is meant to replace.
Limitations (as reported by users on G2):
- Interface refinement: Some users feel the graphical interface has room for polish and could be made more intuitive in places.
- Initial setup and documentation: A few users found the onboarding documentation could be clearer, particularly when configuring cloud traffic sources such as flow logs, which can extend the initial setup time.
- Very large or complex environments: Some users note that deep customization or integration with certain niche tools can feel limited in highly complex environments.
2. SolarWinds Virtualization Manager
![]()
SolarWinds Virtualization Manager (VMAN) is virtual machine management and monitoring software, available both as part of SolarWinds Observability Self-Hosted and as a standalone Orion module. It monitors the health and performance of virtual machines across hybrid environments, tracking metrics such as CPU, memory, and I/O usage. It works with VMware vSphere, Microsoft Hyper-V, and Nutanix AHV environments. Beyond monitoring, it adds capacity forecasting, VM sprawl control, and recommendations to address performance issues. It runs self-hosted, behind the firewall, which is relevant for teams with security or compliance requirements.
Key features include:
- VM performance monitoring: Tracks virtual machine health and resource use — CPU, memory, and I/O — across on-premises and cloud environments to identify bottlenecks. Real-time monitoring is used to surface performance issues so they can be addressed before they affect operations.
- Capacity planning and forecasting: Uses historical usage trends to predict future VM and storage needs, helping teams plan upgrades and avoid over-provisioning. The goal is to prevent capacity-related performance problems and the downtime that can follow them.
- VM sprawl control: Identifies unused or underutilized virtual machines and provides recommendations to reclaim resources. Managing sprawl this way is intended to improve resource efficiency across the virtual environment.
- Predictive recommendations and remediation: Provides actionable recommendations based on predictive analysis to resolve active performance issues and balance VM workloads. Fixes can be scheduled during maintenance windows to limit disruption.
- Multi-hypervisor and Nutanix support: Monitors VMware vSphere and Microsoft Hyper-V environments and also tracks Nutanix AHV, gathering metrics such as CPU, memory, and storage utilization across the hybrid environment from a single console.
- Chargeback reporting: Generates detailed reports on resource usage so costs can be allocated to teams or departments based on their actual VM consumption, which supports budgeting and cost allocation.
Limitations (as reported by users on PeerSpot):
- Pricing: Several users consider the product expensive relative to its scope.
- Stability concerns: Some users reported occasional stability issues, such as the appliance locking up and needing a reboot, though these were generally resolved through support and upgrades.
- Reporting learning curve: Ad hoc and query-based reporting can take time to learn for administrators who are not used to that style of reporting.
- Platform integration gaps: Some users would like broader integration with additional virtualization platforms and wider out-of-the-box support for vendor-specific monitoring data.
3. Device42
![]()
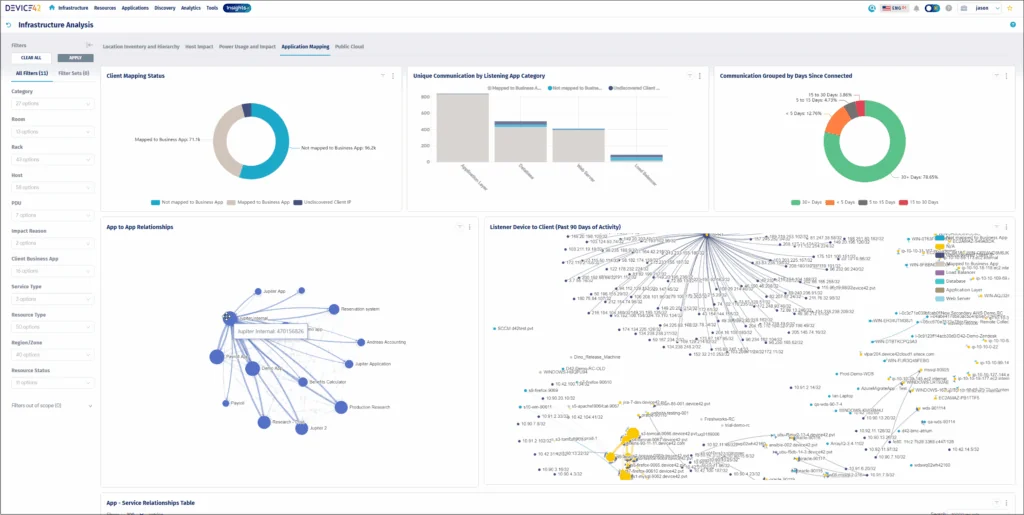
Device42, a Freshworks company, is an agentless IT discovery and dependency mapping platform. It automatically discovers hardware, software, and application dependencies and builds a centralized map of the relationships between them. Discovery runs agentlessly using native Windows (WMI) and Linux (SSH) protocols, and SNMP for network hardware. It identifies deployed applications along with their versions and manufacturers, and the service dependencies, protocols, and ports between them. In a DR planning context, this visibility helps teams understand which systems depend on which before an outage forces the question.
Key features include:
- Agentless discovery: Discovers applications, dependencies, manufacturers, and versions across the environment without installing agents, using WMI for Windows, SSH for Linux, and SNMP for network hardware. This builds an inventory of what exists across hybrid infrastructure.
- Service dependency mapping: Automatically discovers service-to-service dependencies along with the protocols and ports involved, and visualizes application-to-application and application-to-server relationships. It can build dependency maps for machines that cannot be reached directly by using NetFlow data.
- Impact charts: Generates dynamically created impact charts that show the downstream effect of a given application or component. These are intended to reduce risk during migrations and change control by exposing interdependencies before changes are made.
- Move group creation: Lets teams build move groups from the discovered dependency data, which is useful when planning migrations or grouping systems that must move or be recovered together.
- Reporting and visualization: Produces dependency lists, charts, and diagrams that can be exported to Excel or CSV or sent to an external database, and the charts are Visio-compatible for documentation purposes.
- APIs and integrations: Provides flexible APIs to work with the discovered data and integrate Device42 with other products, allowing the dependency data to feed external systems and workflows.
Limitations (as reported by users on G2):
- Setup and learning curve: Several users find the platform complex to set up and navigate at first, with a learning curve that can slow early productivity, particularly for smaller teams.
- Manual upgrades and bulk operations: Some users report that upgrades require significant manual effort, such as building a new VM, and that bulk deletion of assets can be time-consuming.
- Reporting gaps: Users note limits in reporting, including difficulty exporting certain change details, and say the documentation needs frequent updating.
- Scalability with containers: Some users find Kubernetes integration limited at high node counts.
Enterprise Backup and Replication Platforms
These platforms are built for larger, mixed estates and emphasize broad workload coverage, security, and orchestrated recovery.
4. Veeam
![]()
Veeam Backup & Replication is the backup and recovery engine of the Veeam Data Platform. It protects virtual, physical, and cloud workloads and provides instant recovery, immutable storage, and replication. It covers VMware, Microsoft Hyper-V, and Nutanix AHV, along with Windows and Linux servers, NAS, and workloads on AWS, Azure, and Google Cloud. It is deployed as a hardened, Linux-based software appliance with automated updates. Much of the platform is oriented around verified, clean recovery and resilience against ransomware and malware.
Key features include:
- Cross-platform backup and recovery: Protects VMware, Hyper-V, and Nutanix AHV virtual machines, Windows and Linux servers, NAS, and AWS, Azure, and Google Cloud workloads. Backups are portable and self-describing, which allows recovery or migration across hypervisors and clouds without lock-in.
- Instant recovery: Provides Instant Recovery to meet tight RPOs and RTOs, including instant recovery to Microsoft Azure, so critical workloads can be brought online quickly during an outage while full restores proceed. Orchestrated runbooks coordinate recovery across sites or clouds.
- Immutable, Zero Trust storage: Uses immutable repositories together with Zero Trust access controls, role-based access control, four-eyes approvals, and SAML SSO to reduce the risk of backups being altered or deleted, whether by malware or by accidental or malicious action.
- Malware detection and clean recovery: Performs inline malware analysis, anomaly alerts, and sandbox scanning of restore points, and can restore to an isolated environment to validate a known-good point before returning data to production, which reduces the risk of reinfection.
- High availability: Built-in high availability for the backup server, delivered through the Veeam Software Appliance, keeps backup and recovery services online during planned or unplanned outages with rapid failover and without additional clustering products.
- Security and compliance reporting: The Security and Compliance Analyzer checks configurations, roles, and backup settings against best practices, and central logs and reports provide evidence of immutability, verification frequency, and access controls for audits.
Limitations (as reported by users on G2):
- Initial configuration: Some users find the initial storage configuration tricky and would like more transparent licensing.
- Console performance at scale: A few users note the console can feel heavy when managing large-scale environments.
- Cost: Some users say pricing can be higher than alternatives, which may matter for smaller budgets.
- Learning curve: Users without prior backup experience report it can take time to understand the full range of functions.
5. Cohesity DataProtect
![]()
Cohesity DataProtect is an enterprise backup and recovery platform that unifies data protection across on-premises, cloud, and SaaS environments. (Cohesity acquired the Veritas NetBackup enterprise data protection business in late 2024, which is why Veritas no longer appears here as a standalone option.) It centralizes management through the Helios control plane and stores backups as immutable snapshots. It supports a broad set of hypervisors, databases, applications, NAS, and cloud workloads, and is built around instant, large-scale recovery.
Key features include:
- Unified, centralized protection: Protects workloads across on-premises, edge, and cloud locations from a single management platform, Helios. This reduces the need for separate point tools and gives centralized visibility and control across the data estate.
- Broad workload support: Covers hypervisors including VMware vSphere (with vSphere 9 and VMware Cloud Foundation), Nutanix AHV, Microsoft Hyper-V, RHOV, Oracle OLVM, and OpenStack, as well as databases such as Oracle, SQL Server, MongoDB, and Cassandra, plus NAS, physical servers, cloud (AWS, GCP, Azure, OCI), and Microsoft 365.
- Instant mass restore: Recovers VMs, files, and application objects at scale, using unlimited, fully hydrated snapshots to reduce recovery time objectives to minutes and eliminate slow, chain-based backup dependencies. A global search locates data across workloads and locations from one interface.
- Multilayered security: Applies Zero Trust security with granular RBAC, MFA, and SSO, immutable snapshots that cannot be accessed or altered from outside the service, DataLock immutability policies, and hash-based threat scanning to protect backups against ransomware.
- Recovery orchestration: RecoveryAgent builds automated recovery blueprints for disaster and cyber recovery, letting teams create, test, and validate recovery plans and orchestrate the workflows that reduce the risk of data loss during a recovery.
- Compliance and deployment options: Offers FIPS certification and on-premises or private-cloud deployment, including an air-gapped, self-managed Helios option, and uses built-in deduplication and compression to reduce storage consumption.
Limitations (as reported by users on PeerSpot):
- Initial setup complexity: Some users report the initial setup is complex and requires careful planning, particularly for teams with limited technical expertise.
- Reporting: Users note reporting is limited and would benefit from more detailed, customizable options.
- Legacy and storage compatibility: Some users cite limited compatibility with certain storage arrays and legacy systems, and constraints around Windows Failover Cluster.
- Documentation and database coverage: Frequent feature releases mean documentation can lag, and some users want improvements such as SQL object-level restore and broader database support.
6. Acronis Cyber Protect

Acronis Cyber Protect combines backup, cybersecurity, disaster recovery, and endpoint management in a single agent and console. It protects physical, virtual, cloud, and mobile environments, offering full-image and file-level backup with immutable backup options. Its disaster recovery works by failing over to cloud replicas of applications and data, which are scanned for malware before restoration. It supports a wide range of systems, including VMware vSphere, Hyper-V, Nutanix, Proxmox, and others, and is licensed per protected workload on a subscription basis.
Key features include:
- Integrated backup: Provides full-image and file-level backup for physical, virtual, cloud, and mobile environments, with immutable backup, continuous data protection, and rapid recovery. Backup configuration is flexible, with multiple storage options to fit different infrastructure and compliance needs.
- Disaster recovery via cloud replicas: Enables failover to secure cloud replicas of applications and data so operations can resume after an outage. Before restoring to the primary site, replicas are scanned for vulnerabilities and malware, and runbooks are used to speed recovery and reduce RTOs.
- Integrated security: Includes anti-malware and antivirus, advanced threat monitoring, exploit prevention, and vulnerability assessments within the same platform, and scans backup data for malware to help prevent reinfection during recovery.
- Endpoint management: Adds endpoint management through one agent and console, with asset discovery, patch management, software and hardware inventory, remote monitoring, and scripting (Cyber Scripting) to manage and secure endpoints.
- Broad system support: Protects VMware vSphere, Hyper-V, Nutanix, Azure VM, Proxmox, Citrix Hypervisor, Scale Computing, Red Hat (RHEV/RHV/oVirt), Oracle LVM, and Virtuozzo, along with Windows and Linux servers, workstations, mobile devices, Microsoft 365, and Google Workspace.
- Email archiving and compliance: Provides searchable SaaS email archiving for Microsoft 365 with immutable storage and audit logging, and the platform maps to regulatory frameworks such as GDPR, HIPAA, and NIS2.
Limitations (as reported by users on G2):
- Learning curve and setup: Some users report a learning curve and find configuration and setup complex.
- Support: A number of users describe support response as slow or inconsistent.
- Cost: Some users consider the product expensive.
- Reliability and integration: Some users report occasional backup corruption and version-compatibility challenges, and would like better database and platform integration and reporting.
7. HPE Zerto Software
![]()
HPE Zerto Software is a disaster recovery, cyber resilience, and workload mobility solution built on continuous data protection (CDP). Rather than relying on periodic snapshots, it replicates changes in real time to a recovery site on-premises or in the cloud, which reduces data loss to seconds. It uses journal-based recovery to roll back to a point just before an incident such as a ransomware attack. It supports VMware, Microsoft Hyper-V, Azure, and AWS, and is deployed as a virtual appliance. Automation and orchestration handle failover, testing, and recovery.
Key features include:
- Continuous data protection: Uses change-block-based continuous replication to capture writes in real time to a secondary site, so recovery points are measured in seconds rather than the hours or days typical of periodic backups. This is the core mechanism behind how Zerto limits data loss.
- Journal-based recovery: Maintains a journal of changes that allows recovery to many points in time, enabling rollback to a point just before an incident. This is used for both disaster recovery and recovery from ransomware or human error.
- Ransomware detection and recovery: Includes real-time encryption detection to identify ransomware activity, combined with continuous replication and immutable data copies, so teams can recover to a clean point without paying a ransom or enduring a long outage.
- Workload mobility and migration: Uses automation, orchestration, non-disruptive testing, and real-time replication to move workloads between on-premises and cloud platforms without vendor lock-in, supporting migrations as well as recovery.
- Multi-platform support: Supports native virtualization platforms including VMware and Microsoft Hyper-V, plus Microsoft Azure and AWS, and integrates across on-premises, hybrid, and cloud environments for both recovery and migration scenarios.
- Appliance-based deployment and management: Is deployed by configuring a virtual appliance that deploys additional appliances for replication where needed, with management, dashboards, alerts, and non-disruptive recovery testing handled from a management interface.
Limitations (as reported by users on PeerSpot):
- Cost and licensing: Users frequently cite high cost and complex licensing.
- Base OS requirement: Some users note it requires Windows Server as the base operating system, which limits deployment options.
- Storage overhead: Continuous replication journals can grow storage usage quickly, requiring additional capacity.
- Support and interface: Some users would like faster support response and a more intuitive interface with more customizable reporting, especially for large installations.
Backup and Replication for SMBs and Virtual Environments
These tools focus on virtual machine protection and tend to emphasize affordability and simplicity, which makes them common choices for smaller IT teams and service providers.
8. NAKIVO Backup & Replication
![]()
NAKIVO Backup & Replication is a backup, ransomware recovery, and disaster recovery solution for virtual, physical, cloud, and SaaS environments, managed from a single web interface. It provides image-based, application-aware, incremental backup and replication, and can be installed on a NAS as an all-in-one appliance. It supports VMware vSphere, VMware Cloud Director, Microsoft Hyper-V, Nutanix AHV, Amazon EC2, physical servers, file shares, Microsoft 365, and Oracle. It positions itself for both SMBs and larger organizations, and includes multi-tenancy for managed service providers.
Key features include:
- Multi-environment backup: Provides incremental, application-aware, image-based backup for VMware vSphere, VMware Cloud Director, Hyper-V, Nutanix AHV, Amazon EC2, Windows and Linux physical machines, SMB/NFS file shares, Microsoft 365, and Oracle Database via RMAN, all from a centralized interface.
- Site Recovery orchestration: Site Recovery builds automated disaster recovery workflows for planned failover, emergency failover, failback, and data center migration in one click, with non-disruptive DR testing. Workflows can include staged power-on, replica re-IP, network mapping, and custom scripting.
- Ransomware resilience: Creates immutable recovery points in public clouds (Amazon S3, Wasabi, Backblaze B2, Azure Blob Storage), in S3-compatible object storage, and in local Linux-based repositories, and supports air-gapped backups on tape to keep copies isolated from production.
- Instant and granular recovery: Offers Flash VM Boot to start VMs directly from backups, instant file and application-object recovery for Exchange, SQL Server, and Active Directory, cross-platform recovery across hypervisors, and physical-to-virtual (P2V) recovery of physical machines as VMs.
- Storage efficiency: Uses incremental backups with native change tracking, global deduplication, adjustable compression, and automatic exclusion of swap and unused blocks, and supports deduplication appliances such as Dell EMC Data Domain, NEC HYDRAstor, and HPE StoreOnce.
- Multi-tenancy for MSPs: Supports up to 1,000 isolated tenants in a single deployment with role-based access control and a self-service portal, and the Direct Connect feature reaches tenant environments over a single port without a VPN, supporting backup as a service and disaster recovery as a service.
Limitations (as reported by users on G2):
- Edition gating: Some users note that several advanced capabilities are only available in higher editions.
- Learning curve and documentation: A few users report a steeper learning curve for advanced features and say documentation could be clearer in places.
- Large-file restore speed: Some users mention that restoring a large individual file can take a while.
- Platform and OS coverage: Some users would like broader hypervisor support and note limited support for certain platforms.
9. BDRShield (formerly Vembu BDRSuite)
![]()
BDRShield, previously known as Vembu BDRSuite, is a cost-focused backup and disaster recovery platform for businesses and MSPs, available with either a cloud-managed or an on-premises console. It protects endpoints, physical and virtual servers, VMs, SaaS applications, cloud workloads, and databases from a single platform. VM backup is agentless for VMware, Hyper-V, and KVM using Changed Block Tracking. It supports hybrid storage across local and cloud destinations and includes a set of ransomware-focused protections.
Key features include:
- Multi-workload coverage: Backs up endpoints (Windows, Mac, Linux), physical and virtual servers, VMs (VMware, Hyper-V, KVM), SaaS applications (Microsoft 365, Google Workspace, Salesforce), cloud workloads (AWS, Azure, Google Cloud), and databases (SQL, Exchange, SharePoint, Oracle) from one platform.
- Agentless VM backup: Uses native hypervisor APIs with VMware Changed Block Tracking and Hyper-V Resilient Change Tracking for agentless, incremental-forever VM backup, which reduces resource use on production systems and avoids guest agents while keeping backups application-consistent.
- Instant recovery: Provides instant VM boot directly from backup storage, granular file- and item-level restore for Exchange, SQL, SharePoint, and Active Directory, rollback to recovery points, live migration of running VMs from backup to production, and automated failover orchestration for DR.
- Ransomware defense: Includes immutable backup storage that prevents encryption or deletion, air-gapped recovery environments isolated from production, automated anomaly detection alerts, and zero-trust data access controls.
- Hybrid storage and flexibility: Stores backups on local disk, NAS, SAN, tape, or cloud (AWS, Azure, Google Cloud), integrates with S3-compatible object storage for long-term retention, and uses built-in deduplication and compression along with cross-site replication for geographic redundancy.
- Centralized management: Offers a centralized cloud or on-premises console to manage backup, secure storage, and recovery across the environment, with backup scheduling down to short intervals to support tighter recovery point objectives.
Limitations (as reported by users on G2):
- Interface complexity: Some users find the interface overwhelming because of the range of functions, and note that some menus are not where they would expect them.
- Linux support: A few users report that support and documentation lean toward Windows and would like stronger Linux coverage.
- Resource requirements: Some users mention the backup server’s minimum memory requirement and that intermediate files are created on servers.
- Occasional version issues: A few users encountered glitches in specific versions and needed knowledge-base articles for some restore operations.
10. Iperius Backup
![]()
Iperius Backup is a lightweight, low-cost backup and replication tool for VMware vSphere/ESXi and Microsoft Hyper-V, including the free ESXi edition. It performs agentless hot backups of virtual machines and can copy them to many destinations, including disk, network, NAS, tape, and cloud. It supports incremental and differential backup using VMware Changed Block Tracking and can replicate VMs between hosts, including incremental replication on ESXi Free. It uses a single perpetual license that covers unlimited hosts and virtual machines.
Key features include:
- VMware and Hyper-V backup: Performs hot, agentless backups of VMware ESXi, ESXi Free, and vCenter virtual machines, and supports Hyper-V including Hyper-V clusters. A single 30 MB installation on Windows can back up any ESXi or Hyper-V server on the network.
- Incremental and differential backup: Supports VMware Changed Block Tracking (CBT/VDDK) so incremental and differential backups copy only the space actually used on disk. This speeds up jobs, makes backups more granular, and reduces the storage required.
- VM replication: Replicates VMs from host to host and datastore to datastore, including block-level incremental replication on ESXi Free hosts without vCenter. It performs a full replica first and then copies only changes, and the replicated machine is immediately bootable if needed.
- Flexible destinations: Backs up to disk, network, NAS, LTO tape, and cloud or remote destinations such as S3, Google Drive, and FTPS, which supports offsite copies for geographic distribution.
- Granular and cross-host restore: Restores individual files or folders directly from an ESXi VM backup without restoring the whole machine, including opening a VMDK to extract files, and restores full VMs to the same or different hosts from specific incremental or differential points.
- Application-consistent Linux backups: Creates application-consistent backups of Linux VMs by quiescing the file system with pre-freeze and post-thaw scripts, configurable per VM, which matters for virtual servers running database or mail services.
Limitations (as reported by users on Capterra):
- Dated interface: Some users describe the interface as dated and note that a few controls do not follow standard Windows layout conventions.
- Tape handling: A few users mention the inability to span multiple tapes or tape drives as a constraint.
- Licensing changes: Some users find license re-activation cumbersome when moving the software between hardware.
- Specific workflows: Some users note that certain tasks, such as backing up Exchange Server VMs, are more involved than expected, and a few reported scheduled backups failing when the disk layout changes.

How to Implement Virtual Server Backups
In this section, I’ll lay out some options for the actual implementation of virtual server backups. The hypothetical infrastructure in this case will be a deployment of 500 virtual servers. I’ll also list some basic cost data, although this comes with the sizable caveat that it does not include other potential costs like supporting infrastructure, network ingress/egress, and other fees.
For a simple, relatively cheap solution, vSphere isn’t a bad choice. An organization can purchase a VMware vSphere Standard license for $1,268.00, giving them the ability to install the ESXi hypervisor on up to 2,000 hosts, which is more than enough to run 500 VMs and fail-over infrastructure.
Going all-in on a homogenous solution means administration and management is simple; system administrators can utilize a simple point-and-click interface to perform a full backup and restore, as well as snapshots of VMs. Unfortunately, this homogeneity limits flexibility in choosing other workload destinations.
For a medium-priced solution that offers more flexibility in workload management, Veeam is a favorite choice for backing up virtual workloads. While their pricing is generally quote-based, their pricing calculator indicates a price of about ~$40k for managing 500 VMs. As noted in the earlier section, users have several choices for their backup and restore destinations, enabling cross-platform usage. Veeam also offers several restore options, including the scripted removal of sensitive data and snapshots.
Organizations that have large deployments, and are fully invested in something like SolarWinds could utilize the SolarWinds Virtualization Manager. While exact pricing details require environment specific quotes, the license for the VMAN starts at $1749, and large SolarWinds deployments can easily eclipse $100,000 USD.
Traditional Infrastructure Can Still Utilize the Cloud
Just because an organization might still depend on traditional, on-premises infrastructure and virtualization technology doesn’t mean they can’t take advantage of the cloud for DR. The geographically disparate, highly available nature of most cloud platforms make them ideal as a backup and restore destination.
The first steps are to identify and categorize the risks. Next, identify what needs to be backed up and what is critical to maintaining business continuity. I would advise any organization to be particularly careful and detailed here; it’s amazing what turns out to be a critical dependency when production goes down.
Meet Faddom
For organizations that just aren’t sure where to get started, or don’t have the resources to develop a comprehensive disaster recovery strategy, a partner organization with expertise and a proven platform for disaster recovery is going to be your best bet.
Faddom’s application dependency mapping platform creates a complete map of hybrid IT infrastructures — both on premise and in the cloud — in under an hour. Start a free trial today!