

The Importance of Disaster Recovery on AWS
Data loss and system downtime can severely impact a company’s financial stability, customer satisfaction, and brand reputation. Using AWS for disaster recovery allows organizations to take advantage of flexible and cost-effective solutions provided by cloud technology. AWS’s global infrastructure offers high redundancy and reliability, ensuring data is secure and accessible regardless of any physical data center issues.
The scalability of AWS also supports growing business needs without requiring large up-front investments for disaster recovery infrastructure. Companies can start small and scale up as they grow, or adjust their resources down during quieter periods. The pay-as-you-go pricing model of AWS helps companies maintain economically feasible disaster recovery capabilities.
How AWS Elastic Disaster Recovery Works
AWS Elastic Disaster Recovery continuously replicated data and systems from the primary site to the AWS environment. This includes physical and virtual servers as well as applications and all their associated data. Replication is low-latency and can be fine-tuned to intervals as short as every few seconds, which significantly reduces the recovery point objective (RPO) and the potential for data loss.
During an outage or disaster, the service quickly activates the failover mechanism. This switches over to the AWS environment as the primary point of operation, minimizing downtime. Recovery time objective (RTO), or the time it takes to get services running again, is reduced as well.
Once primary sites are restored, AWS DRS enables data synchronization back to the original location, and normal operations can resume with minimal disruption. This ensures that continuity and data integrity are maintained throughout the disaster recovery process.
AWS Elastic Disaster Recovery Pricing
AWS Elastic Disaster Recovery (AWS DRS) features simple, predictable, usage-based pricing, enabling organizations to pay only for the servers they actively replicate to AWS. Costs are calculated on an hourly basis, with no upfront costs or minimum fees. This flexible pricing model eliminates the need for long-term contracts and allows organizations to scale their disaster recovery solutions according to their needs.
Pricing Components
- Continuous data replication: Billed hourly per source server at a rate of $0.028 per server.
- EBS volumes: Replication involves creating staging disks on Amazon Elastic Block Store (EBS). Costs vary based on the type and amount of storage required. For example, higher performance gp3 EBS volumes cost $0.08 per GB per month, while lower-cost sc1 volumes are $0.015 per GB per month.
- EBS snapshots: AWS DRS maintains one base snapshot per source disk and additional incremental snapshots, billed at $0.05 per GB per month.
- EC2 instances: Used as Replication Servers, the cost depends on the instance type and usage duration. For example, t3.small instances cost $0.0208 per hour, while m5.2xlarge instances are $0.384 per hour.
Pricing Example: Monthly Replication of 100 Servers
Assuming a setup with 100 on-premises servers running critical applications for 730 hours per month:
AWS DRS costs:
- 100 servers * $0.028 per hour * 730 hours = $2,044.00
EBS volume costs:
- 15TB of gp3 storage at $0.08 per GB/month = $1,200.00
- 15TB of sc1 storage at $0.015 per GB/month = $225.00
- Total EBS volume costs = $1,425.00
EBS snapshot costs:
- 30TB base storage + 6.93TB incremental (3.3% daily change for 7 days)
- $0.05 per GB/month * 36.93TB = $1,846.50
EC2 instance costs:
- 14 t3.small instances and 3 m5.2xlarge instances
- Total monthly EC2 costs = $1,053.54
Total monthly cost: $6,389.03
Related content: Read our guide to IT disaster recovery plan
Tutorial: Getting Started with Elastic Disaster Recovery
Here’s an overview of how to set up and use AWS DRS.
Initial Setup
To begin using DRS, you need to configure it in each AWS Region where you plan to use it. The setup involves defining replication settings and creating necessary roles and permissions:
- Access permissions: Ensure you have the AWSElasticDisasterRecoveryConsoleFullAccess permission or are an admin user of the AWS account.
- Set the default replication settings: Navigate to the AWS Elastic Disaster Recovery landing page and select Set default replication settings. This includes configuring:
- Replication servers: Lightweight Amazon EC2 instances used to replicate data between your source servers and AWS.
- Volumes and security groups: Attach EBS volumes to replication servers and manage inbound/outbound traffic.
- Additional replication settings: Data routing, throttling, Point in Time (PIT) policies, and tagging resources.
- Configure launch settings: You can use default launch settings for drill or recovery instances in AWS, including instance type, private IP settings, and server tags.
- Finalize the setup: Review and initialize the configuration. Adjust settings as needed via the AWS Elastic Disaster Recovery console.
- Add source servers: Install the AWS Replication Agent on your source servers (both Linux and Windows) to enable replication.
Configuring Launch Settings
After adding source servers, configure their launch settings:
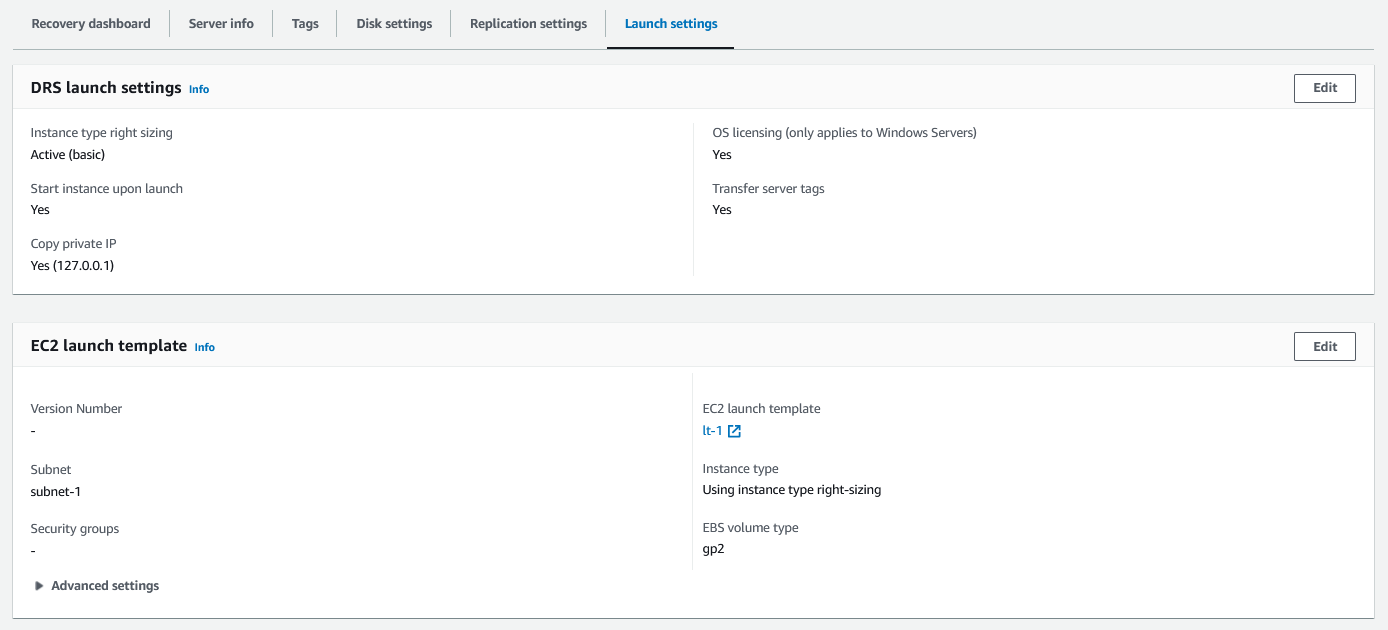
Source: AWS
- Access the launch settings: On the AWS Elastic Disaster Recovery console, click on the hostname of a source server and navigate to the Launch settings tab.
- Edit settings: Configure settings such as:
- Instance type right-sizing: Ensure the instance type matches the source server’s hardware.
- Automatic instance start: Decide whether instances start automatically upon launch.
- Private IP and tags: Ensure the recovery instance’s private IP matches the source server and transfer server tags if needed.
- Customize the EC2 launch template: DRS automatically provides a template for new servers. You can modify the template for individual server requirements.
Launching a Drill Instance
Before initiating a recovery, perform a drill to ensure the source servers function correctly in the AWS environment:
- Initiate the drill: Select the servers to drill and verify their functionality using SSH (Linux) or RDP (Windows).
- Monitor the drill results: Each server’s drill status (success or failure) will be reported. Multiple drills can be conducted, reflecting the source server’s chosen Point-in-time state.
Billing note: Actual AWS resources are used during drills, and you will be billed accordingly. Terminate resources post-drill to avoid unnecessary charges.
Launching a Recovery Instance
After successful drills, proceed with the recovery process to migrate source servers to AWS:
- Schedule a recovery: Perform recovery at a predetermined time, migrating data to recovery instances on AWS.
- Wait for the recovery: DRS can recover one or multiple servers simultaneously. The process deletes previous instances and launches new ones reflecting the source server’s latest state.
- Post-recovery: Data replication continues, and new data on source servers is transferred to the staging area, not the recovery instances. Monitor the recovery status for each server.
Faddom: Supporting Disaster Recovery with Application Dependency Management
While AWS Elastic Disaster Recovery provides a powerful solution for minimizing downtime and ensuring business continuity during outages, understanding the intricate dependencies within your IT environment is crucial for effective disaster recovery planning. This is where Faddom comes in.
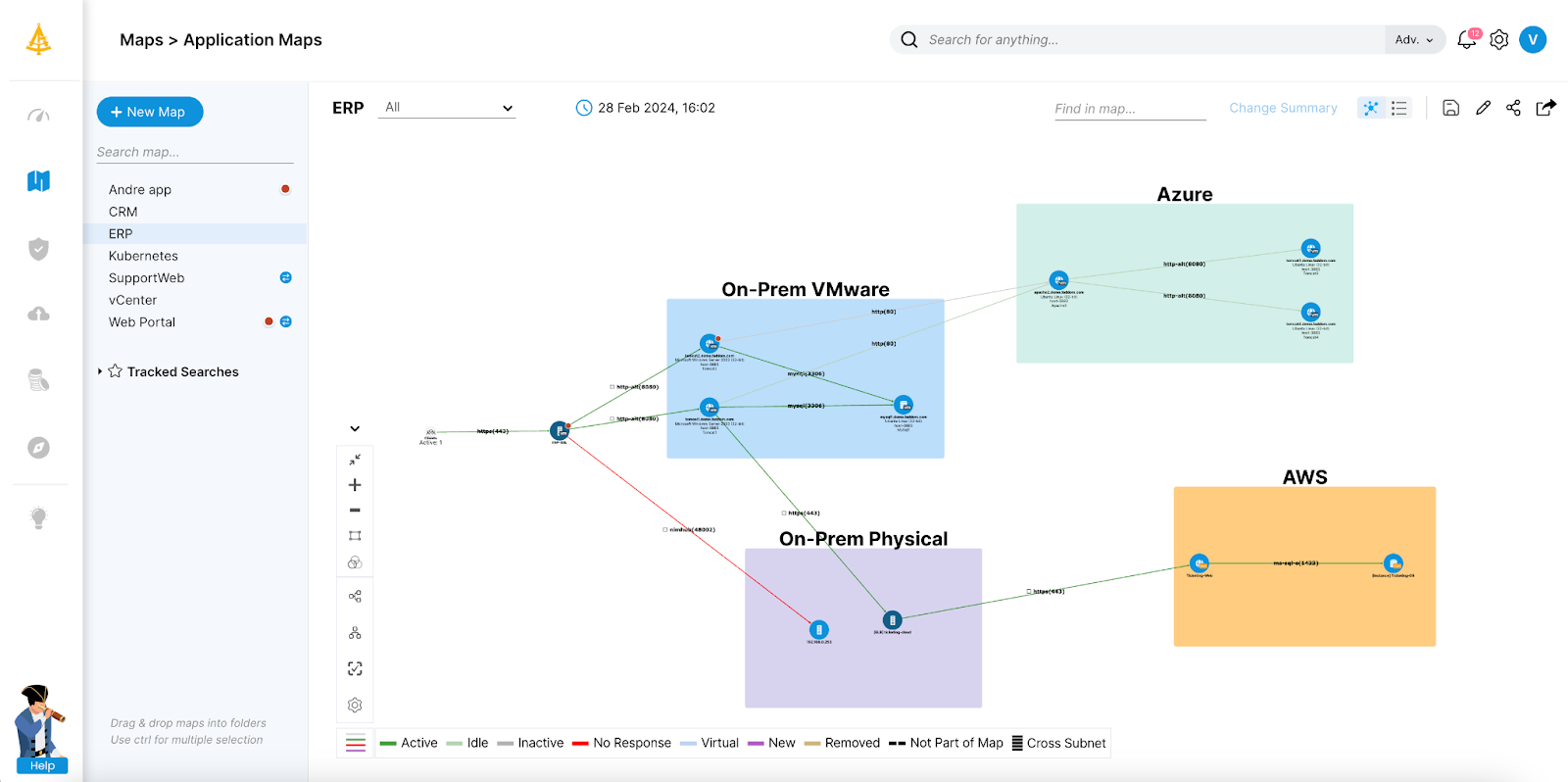
Faddom offers an agentless application dependency mapping solution for visualizing your entire on-premises and cloud infrastructure in as little as one hour. By providing real-time, continuous mapping of all your servers and business applications, Faddom helps organizations understand critical interdependencies, which is essential for planning failover and recovery strategies.
- Agentless and Credential-Free: Deploy without agents or requiring sensitive credentials, ensuring a quick and secure setup.
- Cost-Effective: Starting at just $10,000 per year, Faddom offers an affordable way to gain deep visibility into your IT environment.
- Real-Time Updates: With 24/7 updates, Faddom ensures that your disaster recovery plans are always based on the most current infrastructure state.
- Rapid Deployment: A single IT professional can map the entire organization in under an hour, making it an ideal solution for agile disaster recovery planning.
By integrating Faddom with AWS Elastic Disaster Recovery, organizations can enhance their disaster recovery strategies by clearly understanding their IT environment’s dependencies. This clarity helps in identifying potential failure points, ensuring a more resilient recovery plan.
Check it out on your IT environment with our free trial by completing the form in the sidebar!








{kind=link}