
What Is a Disaster Recovery Plan?
A disaster recovery plan (DRP) is a structured approach to responding to and recovering from disruptive events that impact IT systems, infrastructure, or business operations. It outlines the processes, tools, and responsibilities necessary to restore normal operations quickly and efficiently. DRPs mitigate the effects of natural disasters, cyberattacks, hardware failures, and other disruptions.
By having a proactive recovery strategy in place, organizations can minimize downtime, reduce financial losses, and uphold client trust during emergencies. A well-crafted DRP focuses on protecting both data and operational continuity.
This plan typically includes an assessment of risks, recovery time objectives (RTOs), recovery point objectives (RPOs), backup strategies, and communication protocols. Its purpose is not only to guide immediate response actions but also to establish preventive measures for long-term resilience. Without a functional disaster recovery plan, organizations face prolonged interruptions that can lead to reputational damage or failure to meet regulatory requirements.
This is part of a series about data center migration
Real-World Scenarios and Types of Disaster Recovery Plans
Natural Disaster Contingencies
Natural disasters like earthquakes, hurricanes, and floods can interrupt operations by damaging data centers, power supplies, or critical infrastructure. A disaster recovery plan for such scenarios includes site redundancy, cloud-based backups, and regular drills to test failover systems.
Geodiverse data centers, located in regions with minimal natural disaster risk, are often employed to prevent total data loss in case of regional damage. Organizations must also prepare for post-disaster recovery phases, which involve coordinated communication with employees, partners, and customers. Emergency response teams should be trained to handle hardware replacements, data restoration, and physical infrastructure repairs.
Cybersecurity Breach Response
Cybersecurity breaches are increasing in frequency and complexity, making it essential for organizations to have a recovery plan tailored to digital threats. Such a DRP outlines procedures for isolating the compromised systems, identifying the breach source, and restoring affected data.
Multi-layered data backups, encryption, and endpoint protections play a critical role in any cybersecurity disaster plan. Post-breach recovery also involves reviewing and improving security protocols to prevent recurrence. This includes updating firewalls, conducting threat assessments, and educating employees about cybersecurity best practices.
Supply Chain Disruption Recovery
Supply chain breakdowns, caused by vendor issues, transportation failures, or geopolitical factors, can have ripple effects on business operations. A DRP for these situations prioritizes alternative supplier arrangements, inventory management, and real-time tracking of supply chain activities.
Utilizing predictive analytics and AI helps companies anticipate and mitigate potential disruptions. The recovery phase might involve renegotiating contracts with vendors, establishing new distribution channels, or redesigning logistics workflows.
Data Center Outage Management
Data center outages, resulting from hardware malfunctions, power failures, or human errors, can impact IT operations and data accessibility. To address such incidents, a data center outage recovery plan includes uninterruptible power supplies (UPS), redundant systems, and cloud-based failover solutions to ensure high availability.
Real-time tracking tools identify issues proactively, reducing recovery times. Regular testing of backup systems and simulated outage drills is crucial for ensuring that the plan operates as expected. Organizations must balance on-premise resources with hybrid or fully cloud solutions to achieve seamless recovery and uninterrupted operations.
Infrastructure Failure Mitigation
Infrastructure failures, such as network outages or server crashes, can cripple operations. A disaster recovery strategy for these scenarios includes implementing failover clusters, load-balancing mechanisms, and redundant network paths.
Leveraging software-defined networking (SDN) improves recovery by automating network rerouting and minimizing disruption. Proactive measures like infrastructure tracking and predictive maintenance are vital for addressing vulnerabilities before they result in outages. During recovery, technical teams focus on restoring connectivity, while communication teams ensure end-users remain informed about progress.
Examples and Templates of Disaster Recovery Plans
1. IBM
IBM’s disaster recovery plan offers a template that covers critical elements of a recovery strategy. It begins by defining the major goals of the plan, which are focused on ensuring business continuity and minimizing the operational impact of disruptions to information systems.
The plan organizes essential information into structured sections:
-
- Documentation of personnel: Specifies who is involved in disaster recovery, such as data processing staff and organization charts, ensuring clear role assignments during an emergency.
-
- Application profile: Details software resources in use.
-
- Inventory profile: Records hardware components, helping to identify what systems and tools need restoration.
-
- Data protection: Outlines backup procedures specific to information services.
-
- Recovery steps: Divided into multiple scenarios, including mobile site and hot site recovery. These sections describe actions to take if operations must shift temporarily to an alternate location equipped with backup systems.
-
- Restoring the system: Includes steps for restoring and rebuilding the data center if needed. This involves assessing damage and coordinating reconstruction activities.
-
- Updating the plan: Aims to reflect changes in systems, applications, or procedures.
2. Micro Focus
Micro Focus provides a detailed and professionally structured IT Disaster Recovery Planning Template for organizations building a customized recovery strategy. The template prioritizes IT resilience within the broader context of business continuity and can be adapted to the organization’s infrastructure, risks, and operational needs.
Sections include:
-
- Introduction and intent: Begins with an information technology statement of intent, affirming the organization’s commitment to protecting system uptime, data integrity, and service continuity.
-
- Policy statement: Mandates a formal risk assessment and a comprehensive recovery plan covering critical systems.
-
- Objectives: Outlines the aims of minimizing downtime, assigning clear roles, and ensuring cost-effective and coordinated recovery.
-
- Personnel and communication: Provides structured tools for recording key personnel contacts, creating notification call trees, and identifying external vendors. These resources ensure rapid activation and communication during emergencies.
-
- Emergency activation and team structure: The emergency response team (ERT) and disaster recovery team (DRT) are responsible for assessing damage, triggering the plan, restoring services, and communicating with stakeholders. This section includes procedures for alert escalation, assembly points, and employee contact.
-
- Recovery planning: Defines a fully mirrored recovery site strategy, ensuring instant failover for systems such as IT operations, HR, sales, and web services.
-
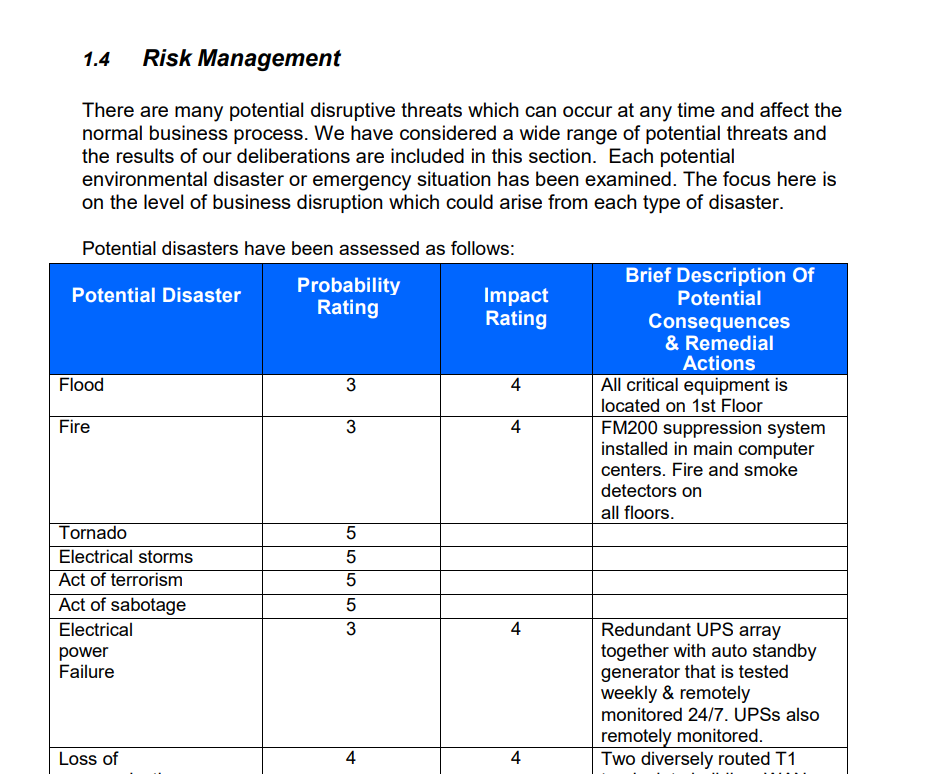
- Risk management matrix: Evaluates the probability and impact of threats like flooding, fires, power failures, or terrorism. Each scenario is linked to predefined remedial actions.
-
- Media, insurance, and legal coordination: Dedicated sections guide interactions with the media, including approved communication strategies and a designated media team. The template also outlines required insurance policies (e.g., business interruption, liability) and describes financial/legal procedures.
-
- Testing, maintenance, and exercises: Encourages periodic exercises to ensure all participants understand their roles. It clarifies that no one “fails” a test.
-
- Appendix A: Provides pre-filled templates for recovering individual systems (e.g., LAN, WAN, remote access, voice communications).
-
- Appendix B: Includes customizable forms for activities like damage assessments, event logging, team mobilization, and process handovers back to business units.
3. University of Southern California (USC)
The University of Southern California provides an IT Disaster Recovery Plan (DRP) Template to support schools and departments in documenting and executing recovery strategies following significant IT disruptions. The template is structured around a phased recovery model and includes editable appendices for institutional customization.
Purpose and Scope
The document outlines goals such as protecting organizational resources, minimizing IT downtime, and enabling quick restoration of essential operations. It focuses on IT-related incidents, excluding personnel or real estate emergencies..
The scope includes:
-
- Network and server infrastructure
-
- Telephony systems
-
- Backup and storage
-
- End-user devices
-
- Organizational software and databases
Plan Structure and Phases
USC’s plan is organized into three core phases:
-
- Activation and notification: Triggered when a disruption exceeds recovery time objectives (RTO). This phase includes outage assessment, plan activation by the IT DRP director, and structured notification procedures using call trees.
-
- Recovery: Focuses on restoring IT services and infrastructure. This includes identifying alternate sites, retrieving backup media, executing recovery steps (Appendix E), and validating system functionality (Appendix F).
-
- Reconstitution: Occurs after critical services have been restored. Activities include validating systems at the original or new site, deactivating the DRP, and documenting lessons learned for plan updates (Appendix G).
Roles and Responsibilities
The plan defines clear roles for recovery personnel, including:
-
- IT DRP director and coordinator oversee activation, manage recovery, and ensure testing and updates.
-
- Alternate personnel serve as backups if primary leads are unavailable.
-
- Recovery teams carry out technical restoration and system validation.
-
- Department head authorizes activation and overall recovery operations.
A comprehensive contact list (Appendix A) and call tree (Appendix B) support clear communication across teams and stakeholders.
Testing, Training, and Documentation
To ensure effectiveness, the plan includes an annual schedule for:
-
- IT DRP awareness training
-
- Testing notification and activation procedures
-
- Validating primary and backup systems
Appendices
The template includes these appendices:
-
- Personnel and vendor contacts (Appendices A–C)
-
- Outage assessment and recovery checklists (Appendices D–E)
-
- Validation testing and reconstitution procedures (Appendices F–G)
-
- Concurrent processing guidelines (Appendix H)
Each section is intended to be fully customized by the school or department to align with its systems and services.

4. Smartsheet
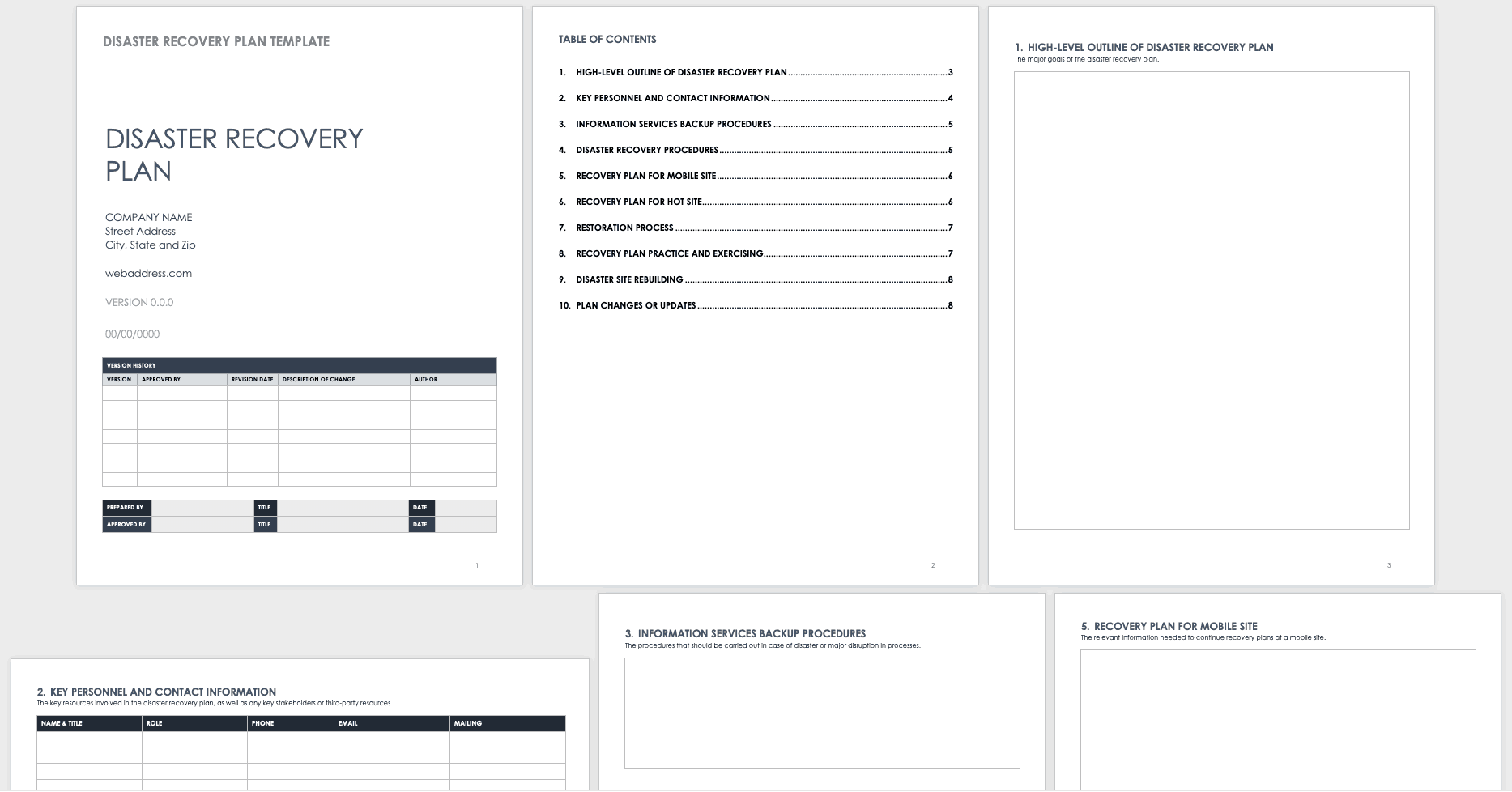
The Smartsheet disaster recovery plan template provides a framework for managing business disruptions. It helps organizations capture and maintain critical recovery information, such as operational procedures, contact lists, backup details, and restoration steps. The template is available in Word, PowerPoint, and PDF formats, making it easy to distribute and use across teams.
The template includes:
-
- High-level outline: Describes the plan’s goals, clarifying the purpose and scope of the recovery efforts.
-
- Version history log: Used to track document updates and approvals.
-
- Key personnel and contact information: Users can record essential roles, phone numbers, emails, and mailing addresses.
-
- Information services backup procedures: Details the necessary steps to protect and retrieve critical data.
-
- Disaster recovery procedures: Identifies the first actions to take in a crisis. The plan includes separate sections for mobile site and hot site recovery.
-
- Restoration process: Outlines how to return systems to full functionality. This includes timelines, technical resources, and responsible parties.
-
- Recovery plan practice and exercising: Encourages organizations to simulate disaster scenarios and test the plan’s effectiveness regularly.
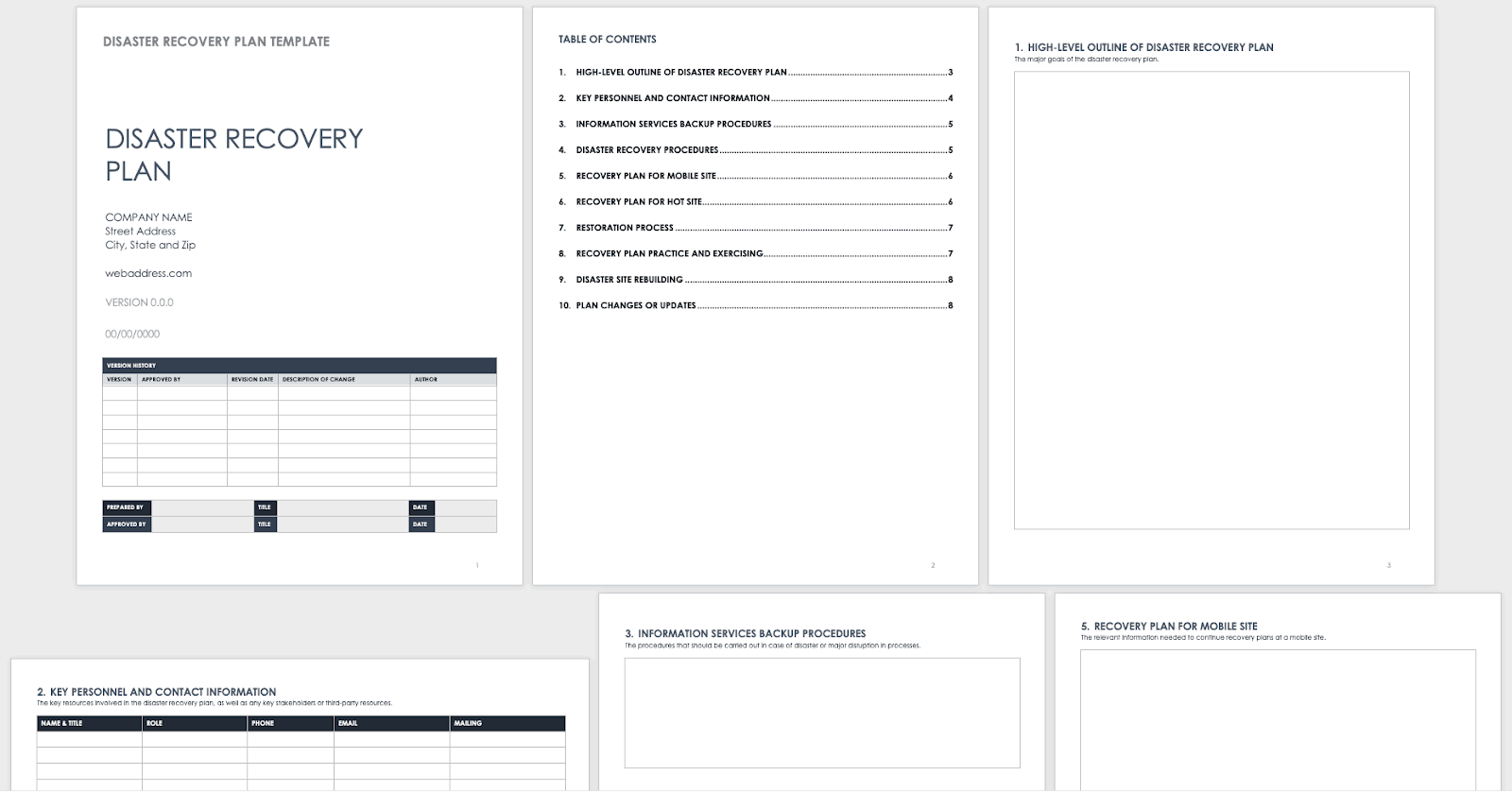
Source: Smartsheet
5. Council of Foundations
The Council on Foundations provides a Disaster and Recovery Plan template for community foundations. This plan addresses organizational, operational, and community-focused concerns that arise during and after emergencies. It emphasizes both internal continuity and external response capabilities, offering a department-level playbook for disaster scenarios.
The plan includes:
-
- Overview: Outlines the foundational goals: protecting personnel, maintaining operations, and continuing essential services such as grant making.
-
- Risks and event scenarios: Categorizes business disruptions into short-term (1–2 days), medium-term (1–2 weeks), and long-term (over 2 weeks) disruptions, with corresponding response strategies.
-
- Plan activation: Specifies that the CEO or designee can initiate the response with guidance from an incident response team (IRT).
-
- Roles and responsibilities: Details roles for the IRT such as the incident commander, IT coordinator, finance lead, and public communications officer, with reference checklists included for each.
-
- Business impact analysis (BIA): Guides foundations in classifying essential functions into high, medium, or low priority, assessing legal, financial, and reputational implications for outages of varying durations.
-
- Recovery activity summary & needs assessment: Expands the BIA into practical requirements—listing personnel, workspace, IT resources, and communication tools needed at various recovery intervals (24 hours to 31+ days).
-
- Vital records management: Identifies necessary documents for recovery, including donor databases, insurance policies, and grant records.
-
- Disaster notification and communications protocols: Addressed through multiple channels such as email trees, hotlines, and the organization’s website. Templates and instructions for activating these systems are included.
-
- Emergency grant making procedures: Allows foundations to respond quickly with funding to vetted community partners. These protocols cover initial outreach, simplified application processes, and tracking mechanisms.
-
- Appendices: These include checklists, vital contacts, hardware inventories, and community resources.

6. Evolve IP
Evolve IP’s disaster recovery plan (DR plan) template is an IT-focused blueprint to help organizations prepare for and respond to a range of disruptions. It serves as both a guide for building a DR plan from scratch and a customizable framework for companies using disaster recovery as a service (DRaaS), especially those utilizing Evolve IP’s own infrastructure and support.
Introduction and Purpose
The template begins by defining what constitutes a disaster—from cyberattacks and power failures to environmental catastrophes and system outages. The bof the plan is to document all infrastructure, roles, and procedures necessary to restore IT functionality and maintain business operations.
Core Sections and Structure
The plan is organized into detailed sections that guide users through disaster recovery planning:
-
- Version control and scope: Tracks updates to the plan and defines which IT systems are covered, including networks, servers, telephony, and software.
-
- Team roles and responsibilities: Specifies disaster recovery teams such as the DR lead, disaster management team, network team, server team, and applications team. Each section includes clearly defined roles, responsibilities, and contact information to ensure accountability during a crisis.
-
- Emergency and external contacts: Provides templates for maintaining up-to-date contact information for internal staff and third-party providers.
-
- System inventory and backup documentation: Includes guidance for listing data assets by criticality, detailing where and how they are stored, and ensuring that backups are retrievable and current.
-
- Recovery procedures: Walks through step-by-step recovery actions based on system severity (e.g., severity one vs. severity two systems), connectivity requirements, server restoration, and application validation.
-
- Architecture and infrastructure documentation: Requires a detailed network and system architecture diagram to support simplified troubleshooting and recovery.
Testing and Maintenance
The template emphasizes the importance of regular testing and maintenance, including:
-
- Rehearsal testing: A walkthrough of the plan with team members to identify gaps.
-
- Failover testing: Bringing systems online in an isolated environment to verify recovery capability.
-
- Live-failover testing: A full production environment failover test, used cautiously after prior validations.
Organizations are also instructed to maintain documentation for each recovered process and continuously revise the plan based on test outcomes and infrastructure changes.

Source: Evolve IP









{kind=link}
{kind=link}