What Is an Incident Response Plan?
An Incident Response Plan (IRP) is a documented, structured, and approved approach to detecting, managing, and recovering from cybersecurity incidents. It outlines roles, responsibilities, and specific steps to minimize damage, reduce recovery time, and prevent future occurrences. Essential phases include preparation, detection/analysis, containment/eradication/recovery, and post-incident activity.
Key components of an incident response plan:
Table of Contents
Toggle- Roles and responsibilities: Definition of the incident response team (IRT), including IT staff, legal counsel, and leadership.
- Definition of incidents: Clear criteria for what constitutes a security incident or breach.
- Communication strategy: Procedures for notifying employees, stakeholders, law enforcement, or customers.
- Actionable procedures: Step-by-step instructions for responding to specific threats (e.g., malware, ransomware).
Steps in an incident response plan (NIST framework):
- Preparation: Training, implementing tools, and establishing policies to ensure the team is ready.
- Detection and analysis: Identifying abnormal activity, validating the incident, and analyzing its scope.
- Containment, eradication and recovery: Isolating affected systems to stop the attack, removing the threat, and restoring systems to normal operations.
- Post-incident activity: Documenting lessons learned to improve future security posture.
Key Objectives of an Incident Response Plan
An incident response plan is built to achieve practical outcomes during and after a security incident. These objectives guide how teams prioritize actions, allocate resources, and measure their response:
- Minimize impact of incidents: Reduce damage to systems, data, and operations by containing threats quickly and preventing further spread.
- Ensure rapid detection and response: Identify incidents early and initiate a structured response without delay.
- Maintain business continuity: Keep critical services running or restore them quickly to avoid prolonged downtime.
- Protect sensitive data: Prevent unauthorized access, loss, or exposure of confidential information.
- Define clear roles and responsibilities: Ensure all team members know their tasks during high-pressure situations.
- Enable effective communication: Establish clear internal and external communication channels, including stakeholders, customers, and regulators.
- Support legal and regulatory compliance: Meet requirements for breach reporting, evidence handling, and data protection laws.
- Facilitate post-incident analysis: Capture lessons learned to improve future response and strengthen security controls.
- Improve overall security posture: Use insights from incidents to identify weaknesses and implement long-term fixes.
- Reduce recovery time and costs: Restore normal operations while minimizing financial loss.
Key Components of an Incident Response Plan
Roles and Responsibilities
Clearly defining roles and responsibilities is critical for an incident response plan. Every team member should know their duties before, during, and after an incident. This includes the core incident response team and stakeholders such as IT, legal, HR, and executive management. Assigning responsibilities in advance prevents confusion and ensures actions are taken promptly.
It is also important to establish a chain of command and escalation paths. This helps the organization respond in a coordinated manner and ensures decisions are made at the appropriate level. Regular training and simulations help everyone understand their responsibilities and execute them under pressure.
Definition of Incidents, Policies and Scope
The policies section of an incident response plan establishes the principles and rules that govern how the organization handles security incidents. These policies outline what constitutes an incident, the criteria for initiating a response, and the legal or regulatory requirements that must be followed. Clear policies ensure consistency and provide a reference point for decision-making.
Defining the scope clarifies which systems, data, and business processes are covered by the plan. This helps focus response efforts on critical assets and ensures relevant scenarios are addressed. The scope should be reviewed to reflect changes in infrastructure, technology, or business operations.
Communication Strategy
A communication plan ensures that information flows during an incident. It specifies who communicates with whom, the approved channels such as email, phone, or secure messaging, and what information can be shared internally and externally. Clear communication reduces confusion and ensures stakeholders are informed at each stage.
The communication plan also covers external notifications, such as informing customers, regulators, or law enforcement when required. It may include pre-approved templates and key contacts. Drills and tabletop exercises help test the communication plan and identify gaps.
Actionable Procedures: Incident Detection and Reporting
Detection and reporting are foundational to incident response. The plan should outline the tools and processes used to monitor systems for potential threats, such as intrusion detection systems, SIEM platforms, or endpoint monitoring solutions. Employees should be trained to recognize and report suspicious activity to the incident response team.
The reporting process must be straightforward and accessible, with clear instructions on how to escalate potential incidents. Timely reporting enables the organization to act quickly and contain threats. Documentation of each reported incident supports post-incident analysis and improvement.
Response Procedures and Playbooks
Response procedures provide step-by-step instructions for handling different types of incidents. These procedures support a consistent response, regardless of who is involved or when the incident occurs. Playbooks, detailed guides tailored to scenarios such as ransomware, phishing, or data breaches, help responders follow established practices.
Playbooks should be reviewed and updated to reflect new threats and lessons learned. They should include actions for containment, eradication, recovery, and post-incident review. Clear playbooks reduce response time and improve coordination.

Lanir specializes in founding new tech companies for Enterprise Software: Assemble and nurture a great team, Early stage funding to growth late stage, One design partner to hundreds of enterprise customers, MVP to Enterprise grade product, Low level kernel engineering to AI/ML and BigData, One advisory board to a long list of shareholders and board members of the worlds largest VCs
Tips from the Expert
In my experience, here are tips that can help you better operationalize an incident response plan:
-
Design for degraded conditions:
Assume identity systems, email, collaboration tools, ticketing, and VPN may be unavailable during a serious incident. Maintain offline copies of the plan, alternate communication paths, emergency access methods, and printed contact trees. -
Pre-authorize high-risk response actions:
During an incident, waiting for approvals can cost hours. Define in advance who can isolate production systems, block customer traffic, disable privileged accounts, shut down integrations, or invoke disaster recovery. -
Map incidents to business services, not just assets:
A compromised server means little to executives unless it is tied to payroll, order processing, patient care, or customer authentication. Maintain a dependency map that links systems, applications, owners, data, vendors, and business impact. -
Create evidence-preservation shortcuts:
Responders often destroy evidence while trying to fix the issue. Build quick-reference procedures for memory capture, disk imaging, log export, cloud snapshotting, and chain-of-custody before containment steps alter the environment. -
Use decision gates in playbooks: Avoid playbooks that are only linear task lists. Add explicit decision points such as “restore or rebuild,” “notify regulator or continue investigation,” “contain immediately or monitor briefly,” and “invoke crisis management.”
Incident Response Lifecycle
1. Preparation
Preparation is the foundation of the incident response lifecycle. This stage involves establishing and training the incident response team, developing policies and procedures, and ensuring necessary tools and resources are available. It also includes creating an inventory of critical assets, identifying potential threats, and conducting risk assessments.
Ongoing education and awareness campaigns help keep staff alert to potential threats and their responsibilities. Drills, tabletop exercises, and testing of security controls help ensure the organization is ready to respond. The preparation phase is continuous and evolves as threats and the environment change.
2. Detection and Analysis
Detection and analysis focus on identifying and understanding security incidents. This involves monitoring systems for signs of compromise, such as unusual network traffic, unauthorized access attempts, or malware infections. Automated tools, logs, and user reports provide data for early detection and triage.
Once a potential incident is detected, analysis determines its scope, impact, and root cause. This stage may involve collecting forensic evidence, interviewing stakeholders, and correlating data from multiple sources. Timely analysis informs response actions and helps limit damage.
3. Containment, Eradication and Recovery
Containment, eradication, and recovery focus on stopping the spread of the incident, removing the threat, and restoring affected systems. Containment strategies might include isolating compromised systems, blocking malicious traffic, or disabling affected accounts. The goal is to limit further harm while preserving evidence.
Eradication involves removing malware, closing vulnerabilities, and cleaning compromised systems. Recovery focuses on restoring systems and data to normal operation through patching, system rebuilds, or restoration from backups. Testing and validation help ensure systems are secure before returning to production.
4. Post-Incident Activity
Post-incident activity supports learning and improvement. This stage includes a post-mortem analysis to identify what worked, what failed, and what can be improved. Lessons learned should be documented and used to update policies, procedures, and training.
This stage also involves generating reports for management, stakeholders, and regulators as required. These reports support accountability and compliance. Improvements based on post-incident reviews help reduce the risk of similar incidents.
Examples of Types of Incident Response Plans
IT Incident Management
IT incident management plans address technology-related disruptions, including hardware failures, software bugs, and network outages. The goal is to restore IT operations while minimizing business impact. These plans include procedures for identifying, logging, categorizing, and prioritizing incidents. They also integrate communication protocols to keep stakeholders informed and ensure proper escalation. Regular review and testing account for changes in infrastructure and organizational needs.
Example:
A software company experiences a network outage after a failed router update. The IT incident management plan guides the team through incident classification, escalation, communication with employees, and service restoration. Operations are restored within hours with minimal business disruption.
Data Breach/Data Leak
A data breach or data leak response plan focuses on incidents where sensitive information is exposed, lost, or stolen. The plan outlines containment actions, such as revoking access or disabling compromised accounts, and guides teams through notification requirements for affected individuals and authorities. It also includes steps for investigating the cause, assessing the extent of exposure, and taking corrective actions. Documentation and forensic analysis support compliance and review.
Example:
An employee accidentally shares a cloud storage folder containing customer records with public access enabled. The response team immediately restricts access, investigates the exposure, notifies affected parties, and reviews security controls to prevent similar incidents.
Ransomware Response
A ransomware response plan provides guidance for handling attacks where data or systems are encrypted by malicious actors demanding payment. The plan covers detection, system isolation, and communication protocols, including whether to engage with attackers. Recovery steps include restoring data from backups, patching vulnerabilities, and conducting an investigation to ensure the threat is removed. Legal and regulatory considerations, such as breach notification requirements, are addressed.
Example:
A manufacturing company detects ransomware encrypting files on several workstations. The response team isolates affected systems, blocks the spread of the malware, restores data from backups, and investigates the initial point of compromise.
Denial of Service (DoS)
A denial of service (DoS) response plan addresses attacks that overwhelm systems or networks, making them unavailable to users. The plan includes procedures for identifying the attack, mitigating its impact through network filtering or traffic rerouting, and communicating updates to stakeholders. After the attack, the plan guides teams through root cause analysis, system restoration, and implementing safeguards to prevent recurrence. Regular testing helps ensure teams can act during real attacks.
Example:
An eCommerce website experiences a sudden flood of malicious traffic that makes the site unavailable to customers. The response team activates DDoS mitigation services, filters malicious traffic, and restores normal service while monitoring for additional attacks.
Related content: Read our guide to incident response management (coming soon)
How to Create an Incident Response Plan
1. Define Goals and Scope
Start by identifying what the plan is expected to achieve. This includes objectives such as reducing response time, protecting critical systems, and meeting compliance requirements. Define which types of incidents are covered and which systems, data, and business units are in scope.
A defined scope prevents gaps and avoids wasted effort on low-priority assets:
- Ensure alignment with business priorities.
- Document exclusions to avoid confusion during an incident.
- Define success metrics, such as mean time to detect (MTTD) or mean time to respond (MTTR). These metrics help evaluate the plan over time.
2. Build Your Incident Response Team
Assemble a cross-functional team with assigned roles. This typically includes security analysts, IT staff, legal advisors, communications personnel, and executive stakeholders. Each role should have responsibilities for different stages of the incident lifecycle:
- Establish escalation paths and decision-making authority so actions are not delayed.
- Assign backups for key roles to ensure coverage during absences.
- Provide training and access to necessary tools.
- Team members should be familiar with logging systems, forensic tools, and communication platforms.
3. Identify Critical Assets and Risks
Create an inventory of systems, applications, and data that are essential to operations. Classify assets based on importance, sensitivity, and potential business impact. This helps prioritize response actions:
- Conduct risk assessments to identify likely threats and vulnerabilities, both external and internal.
- Map these risks to critical assets to understand potential impact.
- Update the asset inventory and risk profile as infrastructure changes or new systems are introduced.
4. Establish Communication Protocols
Define how information will be shared during an incident. This includes internal communication and external communication with customers, regulators, or partners. Specify approved channels and escalation procedures:
- Prepare templates for common scenarios, such as breach notifications or service outage updates.
- Use pre-approved messaging to reduce delays and ensure consistency.
- Define communication security requirements.
- Share sensitive details through secure channels and restrict access to authorized personnel.
5. Develop Playbooks
Create scenario-based guides for handling common incident types such as phishing, ransomware, or insider threats. Each playbook should outline steps for detection, containment, eradication, and recovery:
- Include technical commands, decision points, and fallback actions where relevant.
- Ensure playbooks are version-controlled and accessible to the response team.
- Update playbooks based on new threats or past incidents.
6. Test and Update Regularly
Run tabletop exercises and simulated attacks to validate the plan. Testing helps identify gaps or unclear responsibilities before a real incident occurs:
- Include both technical simulations and communication drills.
- Review and update the plan after major changes to systems, staff, or business operations.
- Incorporate lessons learned from incidents and exercises to improve the plan.
Best Practices for Effective Incident Response Plan
Here are some of the ways that organizations can ensure their IRP is effective.
1. Integrate Attack Surface Management into IRP
Attack surface management (ASM) maintains an up-to-date view of exposed assets, including shadow IT and externally facing services. Integrating ASM into the IRP ensures the response team knows what assets exist and how they are exposed.
This visibility improves prioritization: Teams can identify critical assets and determine whether they are affected. ASM data supports root cause analysis by showing how access may have occurred. Regular synchronization between ASM tools and the IRP keeps asset inventories accurate. ASM also reduces blind spots by discovering new assets and misconfigurations so exposures can be fixed early.
2. Ensure Full Network Visibility
Full network visibility requires insight into traffic, endpoints, users, and system activity. Without this, detection and response rely on incomplete data. Implement logging, monitoring, and telemetry collection across cloud, on-premise, and remote environments.
Centralize data in systems such as SIEM or XDR platforms for correlation and analysis. Include encrypted traffic inspection where appropriate. Retain logs for a sufficient period to trace attacker behavior and understand how long an incident has been active.
3. Prioritize Early Detection and Intelligent Alerting
Early detection reduces the time attackers have to move laterally or exfiltrate data. This depends on well-tuned detection rules and behavioral analysis that identify anomalies. Intelligent alerting reduces false positives and prioritizes high-risk events. Use threat intelligence, machine learning models, and context-aware rules to improve alert quality.
Prioritization improves efficiency: Clear severity levels and automated triage workflows help teams focus on urgent incidents. Continuously tune detection capabilities based on past incidents and emerging threats.
4. Focus on Rapid Containment with Context
Containment should happen quickly but with awareness of business impact and dependencies. Actions such as isolating systems or disabling accounts must consider operational consequences.
There are several ways to speed up containment: Use predefined containment strategies based on asset criticality and incident type. Automation can execute containment actions quickly, with safeguards and approval workflows for high-impact decisions. Staged containment, such as limiting network access before full isolation, can reduce impact while controlling the threat.
5. Align with Incident Response Frameworks
Established frameworks such as NIST, ISO 27035, or SANS provide structured approaches to incident response. Aligning the IRP with these frameworks ensures consistency and compatibility with industry standards.
Framework alignment also supports audits and compliance efforts and provides a common language for teams and stakeholders. Organizations can adapt these frameworks to their environment while keeping core principles intact. Using frameworks helps benchmark maturity and prioritize improvements based on recognized practices.
Strengthening Your Incident Response Plan with Faddom
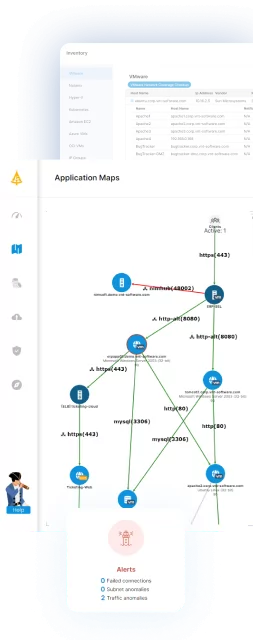
A strong incident response plan depends on knowing exactly what is in your environment and how everything connects—yet most teams struggle to maintain that visibility. Faddom is an agentless, non-intrusive platform that delivers real-time, complete visibility into network connections and dependencies, helping organizations strengthen their security posture and maintain compliance in minutes. Its unique scoring mechanism simplifies complex network activity into actionable insights, prioritizing risks by severity so response teams can address the most critical threats first.
Key capabilities of Faddom:
- Real-time network visibility: Provides agentless, non-intrusive, always-current visibility into network connections and dependencies, deploying in under 60 minutes so teams can see their full environment before, during, and after an incident.
- Risk prioritization scoring: Translates complex network activity into actionable insights and ranks risks by severity, helping responders focus on the most critical threats instead of sifting through noise.
- Lighthouse AI traffic anomaly detection: A deep learning engine that continuously learns your environment to surface unusual traffic and potential threats—including DoS attacks, MITM attacks, DNS spoofing, port scanning, and data exfiltration—while minimizing alert noise over time.
- CVE detection: Identifies known vulnerabilities (CVEs) across the environment, enabling teams to address exposures before they are exploited.
- Shadow IT discovery: Surfaces untracked assets, unauthorized tools, undocumented applications, insecure protocols, and expiring SSL certificates that create security blind spots.
- Lateral movement detection: Monitors north-south and east-west traffic to reveal lateral movement and unexpected connections that signal an active threat.
- Micro-segmentation planning: Maps dependencies to support micro-segmentation planning and enforce security policies, helping contain incidents with full awareness of business impact.
Discover how Faddom can give your incident response team the real-time visibility and context it needs—explore Faddom’s network security solution.