What Is Incident Response Management?
Incident response management is a structured, six-phase approach (preparation, identification, containment, eradication, recovery, and lessons learned) used by organizations to detect, manage, and mitigate cyberattacks. It involves a dedicated team (CSIRT) following a formal plan to minimize damage, reduce recovery costs, and strengthen future security.
Key phases of incident response (SANS/NIST frameworks):
Table of Contents
Toggle- Preparation: Establishing policies, training staff, and creating an incident response plan (IRP).
- Identification (detection): Identifying anomalies and confirming if they are security incidents.
- Containment: Limiting the damage and stopping the attack from spreading (e.g., isolating systems).
- Eradication: Removing the root cause of the incident and the attacker’s footprint.
- Recovery: Restoring systems to normal operation and validating security.
- Lessons learned (post-incident): Analyzing the incident to improve future response procedures.
Core components of effective management:
- CSIRT (Computer Security Incident Response Team): A cross-functional team including IT, security, legal, HR, and executives.
- Incident Response Plan (IRP): A written document that defines roles, responsibilities, and procedures, approved by leadership.
- Communication: A clear, consistent strategy for internal and external stakeholders, focusing on transparency and trust.
- Automation/AI: Utilizing AI tools to speed up investigation and response times.
Key Phases of Incident Response
1. Preparation
Preparation is the foundational phase of incident response and involves establishing policies, procedures, and response plans before an incident occurs. This includes developing an incident response plan, training staff, and ensuring that necessary tools and resources are available. Preparation enables organizations to react quickly when an incident is detected, minimizing confusion and delays. Regular exercises and simulations help teams understand their roles and responsibilities, ensuring that response efforts are coordinated.
The preparation phase also involves identifying critical assets, establishing communication channels, and defining escalation paths. Organizations should maintain up-to-date threat intelligence and relationships with external partners, such as law enforcement and cybersecurity vendors. Investing in preparation reduces the risk of significant disruption or loss during security incidents.
2. Identification (Detection)
The identification phase focuses on detecting potential security incidents as early as possible. This involves monitoring systems and networks for signs of malicious activity, such as unusual traffic patterns, unauthorized access attempts, or changes in system behavior. Early detection is crucial because the sooner an incident is identified, the faster it can be contained and mitigated.
Organizations use a combination of automated tools, such as intrusion detection systems (IDS), and manual analysis to spot suspicious activity. Once a potential incident is detected, it must be classified and prioritized to determine the appropriate response. Identification requires criteria for what constitutes an incident and established procedures for alerting the response team.
3. Containment
Containment aims to limit the spread and impact of an incident once it has been identified. This phase involves isolating affected systems, blocking malicious traffic, and implementing temporary controls to prevent further damage. Short-term containment measures address immediate threats, while long-term containment may involve patching vulnerabilities, updating access controls, or segmenting networks to prevent recurrence.
Effective containment requires balancing rapid action with preserving evidence for forensic analysis. Teams must follow documented procedures to ensure that containment actions do not destroy valuable information. Communication and coordination are critical during this phase to avoid operational disruptions and ensure stakeholders are informed of containment efforts.
4. Eradication
Eradication involves removing the root cause of the incident and eliminating malicious components from affected systems. This may include deleting malware, closing exploited vulnerabilities, and ensuring that attackers no longer have access to the environment. Eradication is a critical step to prevent recurrence and often requires in-depth analysis to identify all traces of the compromise.
Thorough eradication may involve restoring systems from clean backups, applying security patches, and strengthening defenses to address weaknesses exploited during the incident. It is important to verify that all malicious artifacts have been removed and that no backdoors remain. This phase prepares the organization for safe recovery and reduces the risk of reinfection.
5. Recovery
The recovery phase focuses on restoring affected systems and services to normal operation while ensuring that vulnerabilities have been addressed. This may involve rebuilding systems, restoring data from backups, and validating that security measures are in place. Recovery efforts must be managed carefully to avoid reintroducing the threat and to confirm that systems are functional and secure before returning them to production.
During recovery, teams should monitor systems for signs of residual or recurring threats. Organizations should document the recovery process, communicate progress to stakeholders, and review changes made during containment and eradication. Effective recovery reduces downtime and business impact, helping organizations resume normal operations.
6. Lessons Learned (Post-Incident)
The lessons learned phase is a post-incident review to analyze what happened, how it was handled, and what can be improved. This involves conducting a debrief with stakeholders, reviewing incident logs, and assessing the effectiveness of the response. The goal is to identify gaps in the process, update response plans, and share insights across the organization to strengthen future incident response efforts.
Documenting lessons learned helps organizations retain knowledge gained from real-world incidents and prevent similar events. Action items identified during this phase should be tracked and implemented, such as updating policies, improving detection capabilities, or enhancing training programs.
Common Challenges in Incident Response
Delayed Detection
Delayed detection can increase the impact of a security incident. Attackers may use this delay to move laterally within a network, escalate privileges, or exfiltrate sensitive data before discovery. The longer an incident goes undetected, the greater the potential damage, including financial loss, reputational harm, and regulatory penalties. Causes include inadequate monitoring, insufficient logging, or reliance on manual processes that fail to keep pace with evolving threats.
Lack of Skilled Personnel
A lack of skilled personnel hampers effective incident response. The cybersecurity talent shortage means organizations often operate with understaffed or inexperienced teams, making it difficult to respond quickly to incidents. This skills gap can lead to errors in detection, containment, and recovery, as well as longer response times. High demand for incident responders makes recruitment and retention difficult.
Poor Communication
Poor communication during incident response can lead to confusion, duplicated efforts, and missed opportunities to contain threats. When stakeholders are not informed or updates are not shared promptly, coordination and decision-making suffer. This can result in operational disruptions and extended incident duration. Clear communication protocols help ensure everyone understands their roles and the current status of the incident.
Inadequate Documentation
Inadequate documentation undermines incident response efforts. Without detailed records of actions taken, by whom, and when, it is difficult to conduct post-incident analysis or comply with regulatory requirements. Poor documentation also hinders knowledge transfer, limiting the organization’s ability to learn from past incidents.

Lanir specializes in founding new tech companies for Enterprise Software: Assemble and nurture a great team, Early stage funding to growth late stage, One design partner to hundreds of enterprise customers, MVP to Enterprise grade product, Low level kernel engineering to AI/ML and BigData, One advisory board to a long list of shareholders and board members of the worlds largest VCs
Tips from the Expert
In my experience, here are tips that can help you better manage incident response as an operating discipline:
-
Make severity business-led, not tool-led: Do not let alert severity alone drive escalation. Tie severity to customer impact, data sensitivity, revenue exposure, safety, regulatory exposure, and executive visibility.
-
Create an incident commander rotation: Train multiple people to run the incident process, not just investigate. The commander owns cadence, decisions, blockers, handoffs, and executive updates while analysts focus on the technical work.
-
Maintain a live decision log: Record major decisions, who approved them, when they happened, and what evidence supported them. This is invaluable for legal review, audits, insurance claims, and post-incident learning.
-
Use separate workstreams for investigation and restoration: Investigation teams want to preserve evidence; operations teams want systems restored. Splitting these workstreams prevents one objective from accidentally undermining the other.
-
Define minimum evidence before closure: Require proof that persistence is removed, credentials are rotated, vulnerable paths are closed, and monitoring is clean before declaring recovery complete. “System is back online” is not the same as “incident is resolved.”
Core Components of Effective Incident Response Management
CSIRT (Computer Security Incident Response Team)
A computer security incident response team (CSIRT) is a group of professionals responsible for managing and responding to security incidents. The CSIRT coordinates detection, analysis, containment, eradication, and recovery activities to ensure incidents are addressed consistently. This team typically includes security analysts, IT specialists, legal representatives, and communication experts.
A well-structured CSIRT operates under defined roles and responsibilities, with regular training and exercises to maintain readiness. The team serves as the central point of contact during incidents, coordinating communication between technical staff, management, and external stakeholders. Centralizing incident response functions supports consistency and accountability.
Incident Response Plan (IRP)
An incident response plan (IRP) is a formal document that defines how an organization detects, responds to, and recovers from security incidents. It outlines procedures, roles, and decision criteria for each phase of the response lifecycle. The IRP helps teams act consistently and reduces reliance on ad hoc decision-making.
A strong IRP includes escalation paths, severity classifications, communication guidelines, and integration with disaster recovery and business continuity processes. It should be reviewed and updated regularly to reflect changes in infrastructure, threats, and regulatory requirements. Tabletop exercises and simulations help ensure the plan remains practical.
Communication
Communication ensures coordination across technical teams, management, and external stakeholders during an incident. Clear communication reduces confusion, supports decision-making, and aligns response efforts. It includes internal updates and external messaging to customers, partners, and regulators when required.
Effective communication relies on predefined channels, contact lists, and message templates covering notifications, status updates, and escalation triggers. Documenting communication supports compliance and post-incident analysis.
Automation/AI
Automation and AI reduce manual effort and accelerate repetitive tasks in incident response. Tools such as security orchestration, automation, and response (SOAR) platforms can triage alerts, enrich data, and execute predefined actions. This reduces response time and allows analysts to focus on complex investigations.
AI-driven systems can detect anomalies, correlate events across data sources, and prioritize threats based on risk. This improves detection accuracy and reduces alert fatigue. When integrated properly, automation and AI support scalability and consistency.
Metrics and KPIs for Incident Response Management
Measuring incident response performance helps organizations understand how effectively they detect, manage, and recover from security incidents. Metrics and key performance indicators (KPIs) provide visibility into strengths and weaknesses in the response process. They help teams identify bottlenecks, improve decision-making, and justify investments in tools, training, and personnel.
Common metrics used in incident response management include:
- Mean time to detect (MTTD): The average time it takes to identify a security incident from the moment it occurs.
- Mean time to respond (MTTR): The average time taken to contain and remediate an incident after detection.
- Mean time to contain (MTTC): The time required to limit the spread of an incident.
- Mean time to recover: The time needed to restore systems and return to normal operations.
- Incident volume: The total number of incidents detected over a given period.
- False positive rate: The percentage of alerts that are incorrectly identified as incidents.
- Incident severity distribution: The breakdown of incidents by severity level.
- Escalation rate: The percentage of incidents that require escalation to higher-level teams or management.
- SLA compliance rate: The percentage of incidents resolved within defined service level agreements.
- Post-incident review completion rate: The proportion of incidents followed by a formal lessons learned process.
Best Practices for Effective Incident Response Management
Organizations should keep the following practices in mind when planning their incident response management strategy.
1. Maintain Complete Real-Time Visibility of Your IT Environment
Real-time visibility allows teams to detect and understand incidents as they happen. This requires centralized logging, continuous monitoring, and integration across endpoints, networks, cloud services, and applications. Tools such as SIEM and EDR help aggregate and correlate data, giving analysts a unified view of activity.
Without visibility, incidents remain hidden or are detected too late:
- Organizations should ensure logs are complete, time-synchronized, and retained for analysis.
- Visibility should also extend to user activity and API interactions to provide full context during investigations.
- Visibility should support historical analysis: teams should be able to query past events to trace attacker behavior and identify when a breach started.
2. Build and Maintain an Accurate Asset and Dependency Inventory
An accurate inventory of assets is critical for incident response. Teams need to know what systems exist, where they are located, and how they are connected. This includes hardware, software, cloud resources, and third-party services. Dependencies between systems must also be mapped. During an incident, this helps assess impact and prioritize response actions. Automated discovery tools can keep inventories up to date, reducing blind spots and ensuring no critical asset is overlooked.
A well-organized inventory is crucial:
- Assets should be classified based on criticality and sensitivity.
- Systems that handle sensitive data or core business functions should be clearly identified.
- Teams should be able to focus on protecting high-value targets and allocate resources appropriately.
3. Prioritize Fast Detection with Contextual Awareness
Speed matters, but raw alerts are not enough. Detection must include context such as user identity, asset criticality, and threat intelligence. This helps distinguish real threats from noise and ensures high-risk incidents are addressed first. Contextual awareness reduces alert fatigue and improves decision-making. By enriching alerts with relevant data, analysts can quickly understand what is happening and why it matters. This supports faster triage and more accurate prioritization.
For effective prioritization:
- Organizations should baseline normal behavior across systems and users.
- This makes it easier to detect anomalies that indicate compromise.
- Behavioral analysis should be combined with contextual data to improve detection quality and reduce missed threats.
4. Accelerate Root Cause Analysis
Root cause analysis identifies how an incident started and progressed. Delays in this step can lead to incomplete remediation and repeated incidents. Automation can gather and organize evidence, reducing manual effort. Clear documentation and standardized workflows improve consistency.
Faster root cause analysis supports effective eradication and strengthens defenses against similar attacks:
- Teams should use tools that support timeline reconstruction, attack path analysis, and event correlation.
- It is important to preserve forensic evidence during this process.
- Proper handling of logs, memory data, and affected systems ensures analysis is accurate and defensible, especially for incidents with legal or regulatory implications.
5. Enable Faster Containment Through Network Insight
Network-level visibility helps stop the spread of an attack. Understanding traffic flows, segmentation boundaries, and communication patterns allows teams to isolate affected systems quickly. This reduces the risk of lateral movement.
Deeper network insight enables targeted containment:
- Organizations should implement network monitoring and segmentation controls that can be enforced during incidents.
- Predefined containment strategies, such as isolating endpoints or blocking malicious IP addresses, help teams act without delay.
- Instead of shutting down entire systems, teams can isolate affected segments or connections. This limits business disruption while reducing the impact of the incident.
Strengthen Every Phase of Incident Response with Real-Time Infrastructure Visibility from Faddom
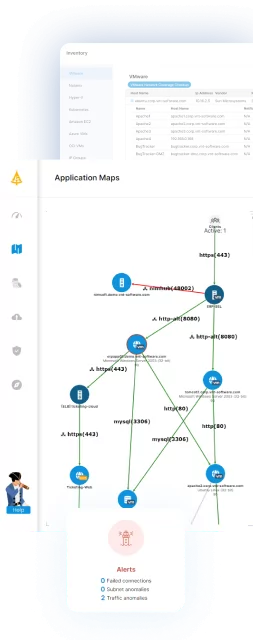
Effective incident response depends on knowing exactly what is in your environment and how everything connects—yet most teams discover blind spots only after an attacker has already moved through them. Faddom’s agentless, non-intrusive platform provides real-time, complete visibility into network connections and dependencies, helping security teams strengthen their posture and maintain compliance in minutes rather than weeks. By turning complex network activity into clear, prioritized insights, Faddom gives responders the context they need to detect, contain, and recover from incidents faster.
Key capabilities of Faddom:
- Real-time visibility into connections and dependencies: Faddom continuously maps how servers, applications, and services communicate across hybrid environments, giving responders an always-current view of the infrastructure during an active incident.
- Agentless, non-intrusive deployment: Because the platform requires no agents, credentials, or firewall changes and works passively, teams can gain visibility without disrupting production systems or destroying forensic evidence.
- Severity-based risk prioritization: A unique scoring mechanism simplifies complex network activity into actionable insights and ranks risks by severity, helping teams address the most critical threats first.
- Shadow IT and undocumented asset discovery: Faddom surfaces untracked assets, undocumented applications, and the protocols and services they use—closing the blind spots that often become an attacker’s entry point.
- Micro-segmentation and policy support: The platform reveals real communication patterns, enabling teams to plan micro-segmentation, isolate affected segments, and reinforce security policies to limit lateral movement during containment.
- Insecure protocol and certificate insight: Faddom helps identify insecure protocols still in use and track certificate expiration dates, reducing the misconfigurations that increase incident risk.
Discover how Faddom can give your incident response team the real-time clarity it needs to act with confidence—learn more about network security with Faddom.