What Is IT Incident Management?
IT incident management is the structured process used by IT teams to detect, analyze, and resolve service disruptions, such as outages or software bugs, to restore normal operations quickly and minimize business impact. Following frameworks like ITIL, it involves logging, categorizing, prioritizing, investigating, resolving, and documenting incidents to ensure high uptime and user satisfaction.
Key stages in the incident management process:
Table of Contents
Toggle- Identification and reporting: Detecting issues through monitoring tools or user reports.
- Logging and categorization: Recording the incident, classifying it, and assigning priority based on impact and urgency.
- Investigation and diagnosis: Analyzing the root cause and determining the best resolution path.
- Resolution and recovery: Implementing a fix (e.g., patching, hardware replacement) to restore service.
- Closure and review: Formally closing the ticket and performing a post-incident review to prevent recurrence.
Incident management vs. problem management:
- Incident management focuses on restoring service as quickly as possible (a temporary or quick fix).
- Problem management focuses on finding the root cause of one or more incidents to prevent future occurrences (a permanent solution).
Objectives of IT Incident Management
The objectives of IT incident management define the outcomes the process is expected to achieve. They guide how teams respond to incidents, prioritize work, and measure success in maintaining service reliability:
- Restore normal service operations as quickly as possible
- Minimize the business impact of incidents
- Ensure consistent and standardized incident handling
- Enable accurate logging and tracking of incidents
- Support effective prioritization based on impact and urgency
- Maintain clear and timely communication
Incident Management vs. Problem Management
Incident management and problem management are often confused but serve distinct purposes within IT service management.
Incident management focuses on restoring service after an interruption or degradation, regardless of the underlying cause. The process is reactive and emphasizes immediate resolution to minimize business impact. This may involve workarounds or temporary fixes while further investigation occurs.
Problem management aims to identify and address the causes of recurring incidents. It is proactive and seeks to prevent future incidents by analyzing trends, conducting root cause analysis, and implementing long-term solutions. While incident management handles the symptoms, problem management addresses the underlying cause.
Together, these practices support both rapid recovery and long-term stability in IT environments.
Key Stages in the IT Incident Management Process
1. Identification and Reporting
Incident identification is the first step in the incident management process. Users, automated monitoring systems, or IT staff may detect incidents, such as application errors, network outages, or degraded performance. Prompt reporting ensures that incidents are addressed before they escalate and cause significant disruption. Clear reporting channels, such as service desks or incident portals, support timely identification and accurate information gathering.
Points to keep in mind:
- Incident identification depends on awareness, training, and accessible tools for all potential reporters.
- Automation can flag anomalies and alert IT teams to issues that may not be immediately visible to end users.
- Rapid and accurate reporting allows incidents to enter the management process quickly, enabling faster triage and response.
2. Logging and Categorization
Once an incident is reported, it must be logged in a central system. Logging includes recording relevant details, such as time of occurrence, symptoms, affected systems, and user impact. Accurate logging ensures traceability, supports communication among IT teams, and creates a record for future analysis. It also supports compliance requirements and historical tracking of incident patterns.
Points to keep in mind:
- Categorization involves assigning each incident to a specific type and priority level based on its nature and business impact.
- This step routes incidents to the appropriate support teams and ensures that critical incidents receive immediate attention.
- Proper categorization supports workflow management and resource allocation and provides a foundation for reporting.
3. Investigation and Diagnosis
During the investigation and diagnosis stage, support teams determine the cause of the incident and identify possible solutions. This phase may involve gathering additional data, consulting documentation, or collaborating with other technical experts. The goal is to understand the scope and source of the issue quickly so that an appropriate response can be defined.
Points to keep in mind:
- Effective investigation depends on access to system logs, monitoring tools, and a knowledge base of past incidents and resolutions.
- Teams may escalate complex issues to specialized groups.
- The speed and accuracy of diagnosis affect resolution time and business impact.
4. Resolution and Recovery
The resolution phase involves implementing corrective actions to restore normal service. Depending on the incident, this could mean applying a temporary fix, restarting services, or deploying a permanent solution. Recovery ensures that affected systems and users return to normal operation and that services function as expected.
Points to keep in mind:
- IT teams provide status updates, instructions, and confirmation when services are restored.
- Proper documentation of the steps taken and outcomes achieved supports future reference and process improvement.
5. Closure and Review
Incident closure marks the formal end of the process for a particular event. Before closing, IT teams confirm that the incident has been resolved, affected users are satisfied, and documentation is complete. Closure also includes updating incident records with details of the solution and any follow-up actions.
Points to keep in mind:
- A post-incident review evaluates the effectiveness of the response.
- This review identifies lessons learned, process improvements, and underlying problems that should be addressed through problem management.
- Regular closure and review practices help reduce the likelihood and impact of future incidents.

Lanir specializes in founding new tech companies for Enterprise Software: Assemble and nurture a great team, Early stage funding to growth late stage, One design partner to hundreds of enterprise customers, MVP to Enterprise grade product, Low level kernel engineering to AI/ML and BigData, One advisory board to a long list of shareholders and board members of the worlds largest VCs
Tips from the Expert
In my experience, here are tips that can help you better adapt to the topic of application dependency mapping (ADM):
-
Define “normal service” precisely: Teams often close incidents too early because the system is technically online. Define normal service using user journeys, transaction success rates, latency, error budgets, and business process completion.
-
Separate restoration from explanation: Do not delay service restoration while searching for the perfect root cause. Restore first when safe, then hand unresolved cause analysis to problem management with clear evidence and ownership.
-
Use impact models for priority decisions: Build predefined impact models for critical services, VIP users, customer channels, revenue systems, and regulatory processes. This prevents priority debates during an active outage.
-
Create incident swarming rules: For complex incidents, avoid endless ticket reassignment. Define when to form a temporary swarm with service desk, infrastructure, application, network, database, and vendor experts in one channel.
-
Track workaround quality: A workaround that restores service but creates manual effort, data inconsistency, security risk, or user confusion should be flagged. Not all resolved incidents are equally healthy.
Key Roles in Incident Management
Incident Manager
The incident manager oversees the incident management process. This role ensures that incidents are logged, categorized, and resolved within defined service levels. The incident manager coordinates resources, monitors progress, and escalates issues as needed. They also serve as the primary point of contact for major incidents, coordinating communication between technical teams, management, and stakeholders.
The incident manager reviews incident trends, reports on key metrics, and drives process improvements. They maintain documentation, conduct post-incident reviews, and ensure compliance with policies and practices.
Service Desk / First-Line Support
The service desk or first-line support team is the initial point of contact for users experiencing IT issues. They receive, log, and categorize incidents, and provide basic troubleshooting and resolution. First-line support aims to resolve as many incidents as possible at initial contact, reducing the workload on higher-level support teams.
Service desk staff need training in customer service, technical skills, and the use of incident management tools. They gather accurate information, set user expectations, and escalate incidents when necessary.
Technical Support Teams
Technical support teams, often referred to as second- or third-line support, handle incidents that cannot be resolved by the service desk. These teams include subject matter experts with specialized knowledge of systems, applications, or infrastructure. They perform in-depth investigation, diagnosis, and resolution of complex incidents, often collaborating across departments.
Technical support teams rely on clear escalation procedures, documentation, and analytical skills. They also update the knowledge base and provide feedback to improve incident management processes and tools.
Stakeholders and Communication Leads
Stakeholders and communication leads keep affected users, business leaders, and other parties informed throughout the incident lifecycle. They coordinate status updates, manage expectations, and ensure that relevant information is communicated clearly. Clear communication reduces confusion during service disruptions.
Communication leads also contribute to post-incident reviews by documenting lessons learned and sharing insights across the organization. Their input helps refine communication protocols for future incidents.
Tools for IT Incident Management
ITSM and Ticketing Platforms
IT service management (ITSM) and ticketing platforms support the incident management process. These tools provide centralized systems for logging, tracking, and managing incidents from initial report to closure. Ticketing platforms offer workflow automation, SLA monitoring, and integration with other IT tools.
ITSM platforms:
- Improve accountability, visibility, and coordination among support teams.
- Enable reporting and historical analysis.
- Support alignment with established processes.
AIOps and Event Correlation Tools
Artificial intelligence for IT operations (AIOps) and event correlation tools use machine learning and analytics to detect, correlate, and prioritize incidents in complex IT environments. These tools identify patterns, reduce redundant alerts, and suggest probable causes for incidents.
By automating detection and initial triage, AIOps tools:
- Reduce response times and allow teams to focus on complex tasks.
- Support faster resolution by linking related alerts and incidents in event correlation.
Monitoring and Observability Tools
Monitoring and observability tools provide visibility into the health and performance of systems, applications, and infrastructure. Monitoring focuses on predefined metrics and alerts, such as CPU usage, latency, or error rates, while observability supports analysis by correlating logs, metrics, and traces.
These tools:
- Help detect incidents early, often before users are affected.
- Send automated alerts to notify teams when thresholds are breached.
- Provide observability, allowing teams to trace issues across distributed systems and understand system behavior under different conditions.
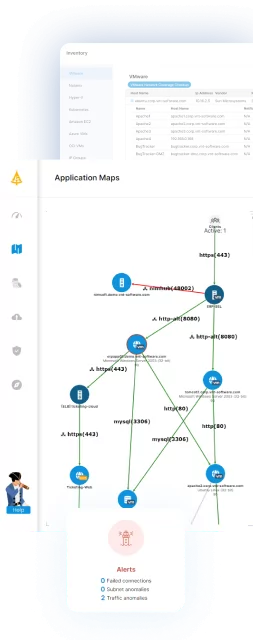
Application Dependency Mapping Tools
Application dependency mapping tools show relationships between applications, services, and underlying infrastructure components. They discover and map how systems interact, showing dependencies across servers, databases, APIs, and network elements.
These tools:
- Support incident diagnosis by identifying affected components and how failures propagate.
- Create dependency maps to show how applications and components interact.
- Reduce troubleshooting time by guiding teams to the likely source of an issue.
Best Practices for IT Incident Management
Here are some of the ways that organizations can ensure effective management of IT incidents.
1. Prioritize Incidents Based on Business Impact
Incident prioritization should be driven by business impact, not just technical severity. Define criteria that combine impact, such as the number of users or services affected, and urgency, such as time sensitivity. This ensures critical services receive immediate attention while lower-impact issues are queued appropriately. A consistent prioritization model improves SLA adherence and resource allocation.
How to implement:
- Teams should review and adjust priority definitions to reflect changing business needs and service dependencies.
- Create a priority matrix that combines impact and urgency to assign consistent incident severity levels.
- Define escalation paths and response targets for each priority level to ensure timely action.
2. Maintain a Centralized Knowledge Base
A centralized knowledge base stores documented solutions, known errors, and troubleshooting steps. It allows support teams to resolve incidents faster by reusing proven fixes and reduces duplication of effort. The knowledge base should be updated after incident resolution. Content must be clear, searchable, and accurate. Over time, it supports training and onboarding, reduces dependency on individual expertise, and improves consistency in how incidents are handled.
How to implement:
- Document incident resolutions, workarounds, and known errors using a standardized format.
- Implement tagging, categorization, and search functionality to make information easy to find.
- Assign ownership for regular content reviews to remove outdated information and maintain accuracy.
3. Enable Real-Time Monitoring and Early Detection
Real-time monitoring tools should detect anomalies and trigger alerts before users report issues. Early detection reduces incident impact and resolution time. Monitoring should cover infrastructure, applications, and user experience metrics. Alerts must be tuned to avoid noise and focus on actionable signals. Integrating monitoring systems with incident management tools enables automatic ticket creation and faster response. This reduces manual effort and ensures incidents are routed to the right teams without delay.
How to implement:
- Deploy monitoring tools across infrastructure, applications, networks, and critical business services.
- Define alert thresholds based on normal operating baselines and regularly tune them to reduce false positives.
- Integrate monitoring platforms with incident management systems to automate ticket creation and routing.
4. Use Data and Metrics to Drive Improvement
Incident management should be measured using metrics such as mean time to resolution (MTTR), incident volume, SLA compliance, and first-contact resolution rate. These metrics show process efficiency and team performance. Trend analysis helps identify recurring issues and bottlenecks. Data supports workflow adjustments and resource planning. Regular reporting and dashboards help stakeholders track performance. These insights enable teams to proactively address systemic issues before they escalate into major incidents.
How to implement:
- Track key performance indicators such as MTTR, incident volume, SLA compliance, and recurrence rates.
- Use dashboards and regular reporting to identify trends, bottlenecks, and areas requiring attention.
- Conduct periodic reviews of incident data to prioritize process improvements and preventive actions.
5. Ensure Continuous Improvement
Continuous improvement involves reviewing incident processes, tools, and outcomes to identify gaps. Post-incident reviews and trend analysis provide insights for refining procedures and preventing future incidents. Improvements should be based on measurable outcomes. This may include updating runbooks, increasing automation, or improving communication protocols. A structured approach ensures the incident management process evolves with organizational needs.
How to implement:
- Establish feedback loops to ensure lessons learned are consistently applied across teams and processes.
- Conduct post-incident reviews for significant incidents and document corrective and preventive actions.
- Regularly update runbooks, workflows, and automation based on findings from incident reviews and performance data.
Resolving IT Incidents Faster with Faddom
Faddom is a real-time, agentless application dependency mapping platform that automatically discovers and maps servers, applications, cloud resources, and traffic flows in under 60 minutes. By turning raw network data into a continuously updated map of how your environment actually operates, Faddom gives IT teams the operational context they need to detect affected components, trace how failures propagate, and restore normal service quickly during an incident.
Key capabilities of Faddom:
- Real-time dependency mapping: Automatically discovers and continuously maps the relationships between servers, applications, and services, so teams can immediately see which components an incident touches and how they connect.
- Agentless, credential-free discovery: Delivers full visibility with no agents, no credentials, and no firewall changes, letting teams stand up incident-ready infrastructure visibility within an hour of deployment.
- AI-driven correlation and analysis: Transforms raw network traffic into real-time application and dependency maps, providing the operational context layer needed to understand, operate, and secure complex hybrid environments.
- Continuous change tracking: Maps business applications and tracks changes in real time, helping teams reduce risk and identify configuration changes that may have triggered a disruption.
- Hybrid and cloud coverage: Visualizes on-premises and cloud infrastructure in a single, always-accurate map, eliminating outdated spreadsheets and siloed visibility.
See how Faddom’s real-time application dependency mapping can help your team diagnose and resolve incidents faster — explore the Faddom platform.