What Is an Incident Response Framework?
An incident response (IR) framework is a structured, six-step process (Preparation, Identification, Containment, Eradication, Recovery, and Lessons Learned) used to detect, manage, and mitigate cyber security incidents. Key frameworks like NIST (SP 800-61) and SANS help organizations standardize procedures, reduce breach impact, and maintain compliance.
Core phases of an incident response framework:
Table of Contents
ToggleMost frameworks follow a similar cycle designed to handle security events efficiently:
- Preparation: Establishing policies, training staff, and deploying tools to handle incidents before they occur.
- Identification (detection and& analysis): Monitoring systems to detect, verify, and analyze suspicious activity to determine if it is a security incident.
- Containment: Limiting the scope and magnitude of the incident to prevent further damage.
- Eradication: Removing the root cause of the incident, such as deleting malware or disabling breached accounts.
- Recovery: Restoring systems to normal operation and validating that they are fully functional and secure.
- Lessons learned (post-incident activity): Reviewing the incident to improve future response procedures and security posture.
Top incident response frameworks:
- NIST cybersecurity framework (CSF) / SP 800-61: Widely recognized for its 4-step life cycle (Preparation, Detection/Analysis, Containment/Eradication, Recovery).
- SANS institute: A six-step process often utilized for its detailed approach to incident handling.
- ISO/IEC 27035: International standard for managing security incidents.
- MITRE ATT&CK: A knowledge base used to guide detection and analysis.
- ENISA: Provides EU-focused guidance on incident response.
- CREST: Offers certification and best practice frameworks for incident response teams.
This is part of a series of articles about incident response plan.
Benefits of Using an Incident Response Framework
An incident response framework brings structure to how organizations handle security events. Instead of reacting in an ad hoc way, teams follow defined steps that improve speed and coordination. This reduces confusion during incidents and helps ensure critical actions are not missed:
- Consistency: Ensures incidents are handled using the same proven process every time. This reduces variability and improves the reliability of outcomes across teams.
- Efficiency: Speeds up detection, analysis, and response. Teams spend less time deciding what to do and more time executing the right actions.
- Compliance: Helps meet regulatory and legal requirements by enforcing documented procedures, audit trails, and reporting standards.
- Faster response times: Predefined workflows allow teams to act quickly, limiting the spread and impact of an incident.
- Improved coordination: Defines roles and responsibilities clearly, reducing miscommunication between security, IT, legal, and management teams.
- Reduced impact: Early containment and structured remediation minimize damage to systems, data, and operations.
- Better decision-making: Provides guidance during high-pressure situations, helping teams prioritize actions based on risk and impact.
- Knowledge retention: Captures lessons learned through post-incident analysis, improving future response efforts.
- Scalability: Allows organizations to handle incidents of varying size and complexity without reinventing the process each time.
- Stronger security posture: Continuous improvement and standardized practices strengthen overall resilience against future attacks.
Core Phases of an Incident Response Framework
1: Preparation
Preparation is the foundation of an incident response framework. In this phase, organizations document policies, procedures, and communication plans tailored to their threat landscape. They assemble and train the incident response team, assign roles, and define how to report and escalate events. Regular exercises, such as tabletop simulations, help identify gaps.
Preparation also includes deploying security technologies and maintaining asset inventories. Organizations implement monitoring tools, establish baselines for normal behavior, and configure logging and alerting systems. Addressing vulnerabilities in advance reduces the likelihood of successful attacks and improves readiness.
2. Identification (Detection and Analysis)
The identification phase focuses on detecting and analyzing potential security incidents. This includes monitoring systems for signs of malicious activity, such as unusual traffic patterns or unauthorized access. Organizations use intrusion detection systems, security information and event management (SIEM) tools, and threat intelligence feeds. Rapid detection limits impact.
When an event is detected, analysts assess severity and determine whether it is an incident. This may require collecting data, correlating logs, and conducting forensic analysis. Accurate identification allows the team to classify the incident and initiate containment. Documenting findings ensures later steps are based on clear information.
3. Containment
Containment limits the spread of an incident. Short-term containment isolates affected systems, such as disconnecting compromised devices or blocking malicious traffic. This prevents lateral movement or data exfiltration while investigation continues. Long-term containment includes applying patches, updating firewall rules, or changing credentials. All actions should be documented for internal review and regulatory reporting. Effective containment reduces impact and prepares for eradication and recovery.
4. Eradication
Eradication removes the root cause of the incident. This may involve deleting malicious files, disabling compromised accounts, or uninstalling unauthorized software. The goal is to eliminate the attacker’s presence and restore system integrity.
Organizations often conduct additional forensic analysis to confirm removal and address underlying weaknesses, such as unpatched software or misconfigurations. A methodical approach prevents reinfection.
5. Recovery
Recovery restores systems and services to normal operation. This includes reinstalling clean backups, validating system integrity, and monitoring for residual threats. Clear communication with stakeholders manages expectations during restoration. After systems are online, additional monitoring may be applied. A successful recovery restores operations and strengthens future readiness.
6. Lessons Learned (Post-Incident Activity)
The lessons learned phase focuses on improvement. After resolution, the team reviews what happened, how the response unfolded, and what should change. This review includes stakeholders and analysis of logs and timelines. Documenting lessons helps update policies and playbooks. Regular refinement improves resilience over time and supports broader information-sharing efforts.

Lanir specializes in founding new tech companies for Enterprise Software: Assemble and nurture a great team, Early stage funding to growth late stage, One design partner to hundreds of enterprise customers, MVP to Enterprise grade product, Low level kernel engineering to AI/ML and BigData, One advisory board to a long list of shareholders and board members of the worlds largest VCs
Tips from the Expert
In my experience, here are tips that can help you better implement incident response frameworks in real environments:
-
Use frameworks as overlays, not replacements: Do not force one framework to answer every need. Use NIST or SANS for lifecycle structure, ISO 27035 for governance, MITRE ATT&CK for adversary behavior, and CREST-style practices for team maturity.
-
Create a framework-to-control crosswalk: Map each framework phase to actual controls, tools, owners, logs, evidence sources, and business processes. This turns abstract framework language into something teams can execute and auditors can validate.
-
Define your “minimum viable response”: For each major incident type, specify the smallest set of actions that must happen within the first 15, 30, and 60 minutes. This keeps teams focused when the full framework feels too heavy during a crisis.
-
Translate framework phases into operational triggers: Teams often know the phases but not when to move between them. Define clear triggers for escalation, containment, legal review, customer notification, recovery approval, and incident closure.
-
Avoid framework theater: Many organizations claim alignment because documents exist. Test whether responders can actually find evidence, isolate systems, contact owners, preserve logs, and make decisions under pressure.
Top Incident Response Frameworks
NIST Cybersecurity Framework (CSF) / SP 800-61
The NIST Cybersecurity Framework (CSF) and SP 800-61 Computer Security Incident Handling Guide are widely adopted standards. NIST outlines preparation, detection and analysis, containment, eradication, and recovery, with continuous improvement through lessons learned. SP 800-61 provides technical guidance, templates, and practices for building an incident response capability. It aligns with regulatory requirements such as FISMA and HIPAA and is updated to address emerging threats.
SANS Incident Response Framework
The SANS Incident Response Framework follows six phases: preparation, identification, containment, eradication, recovery, and lessons learned. It emphasizes practical steps that organizations of all sizes can implement. SANS provides training, playbooks, and checklists to support adoption. It is widely used in commercial and government environments.
ISO/IEC 27035 Incident Management Framework
ISO/IEC 27035 is an international standard for information security incident management. It defines processes for preparing, detecting, reporting, assessing, responding to, and learning from incidents. Organizations pursuing ISO 27001 certification often adopt ISO/IEC 27035. Its risk-based approach supports regulatory compliance and consistent incident handling.
MITRE ATT&CK
MITRE ATT&CK is a knowledge base that categorizes adversary tactics, techniques, and procedures (TTPs). Although not a traditional framework, it informs detection and response strategies. Security teams map attacker behavior to the ATT&CK matrix to identify defense gaps and prioritize response actions.
ENISA Incident Response Framework
The European Union Agency for Cybersecurity (ENISA) provides guidance tailored to European organizations. Its framework addresses regulatory requirements such as GDPR and supports cross-border cooperation. ENISA offers resources including incident classification schemes and reporting templates. It also supports national computer security incident response teams (CSIRTs).
CREST Incident Response Framework
CREST provides standards focused on building and assessing professional incident response capabilities. It emphasizes practitioner competence, certification, and organizational accreditation. CREST defines expectations for roles, escalation paths, evidence handling, and integration with threat intelligence. It is widely used in the UK and aligned with guidance from the National Cyber Security Centre (NCSC).
Best Practices for Implementing Incident Response Frameworks
Organizations can improve their implementation of relevant incident response frameworks by applying these practices.
1. Align Incident Response with Risk Management
Incident response should reflect the organization’s risk profile. Response planning, prioritization, and resource allocation should focus on the assets, threats, and business processes that present the highest risk. Aligning incident response with risk management helps organizations reduce the impact of security events and make informed decisions during incidents.
How to implement:
- Prioritize assets and threats based on business impact.
- Align response priorities with critical business services to ensure high-impact systems receive immediate attention.
- Integrate incident response with enterprise risk management.
- Define severity levels, thresholds, and escalation criteria based on risk assessments.
- Use risk scoring to guide decision-making and resource allocation during incidents.
2. Maintain a Complete, Real-Time Asset Inventory
An accurate asset inventory supports effective response. Teams must know what systems exist, where they are located, and who owns them. The inventory should include cloud resources, APIs, and third-party dependencies to avoid blind spots.
How to implement:
- Automate asset discovery and keep data updated.
- Tag assets by criticality to support prioritization.
- Ensure ownership metadata is accurate so teams know who to contact during incidents.
- Maintain dependency mapping between systems to understand upstream and downstream impact during an incident.
3. Establish Clear Roles, Responsibilities, and Escalation Paths
Clearly defined roles and escalation procedures help teams respond quickly and avoid confusion during incidents. Everyone involved should understand their responsibilities, reporting structure, and decision-making authority. This improves coordination and reduces delays when rapid action is required.
How to implement:
- Define responsibilities for technical responders, incident commanders, legal advisors, and communication leads.
- Assign decision authority in advance to avoid delays during critical moments.
- Document escalation paths and maintain current contact information.
- Conduct regular drills to validate readiness.
- Ensure backup personnel are assigned for key roles to maintain coverage during absences.
4. Implement Continuous Monitoring and Baselines
Continuous monitoring supports early detection. By collecting and analyzing security events in real time, organizations can identify suspicious activity before it escalates into a major incident. Establishing normal behavior baselines helps teams distinguish legitimate activity from potential threats and improves detection accuracy.
How to implement:
- Deploy SIEM, EDR, and network monitoring tools.
- Centralize logs and telemetry to enable correlation across systems and faster investigation.
- Establish baselines for normal behavior and tune alerts to reduce noise.
- Incorporate threat intelligence to add context.
- Continuously refine detection rules based on past incidents and emerging attack patterns.
5. Build and Maintain Incident Response Playbooks
Playbooks help responders act consistently and efficiently during security incidents. They reduce uncertainty by providing predefined procedures for common scenarios, ensuring critical steps are not overlooked. Well-maintained playbooks also improve coordination between teams and accelerate response efforts.
How to implement:
- Include decision points, required tools, and validation steps to ensure consistent execution.
- Keep playbooks updated and test them through simulations.
- Incorporate lessons learned from past incidents to improve accuracy and effectiveness.
- Ensure playbooks are easily accessible during incidents, including offline copies for use in degraded environments.
6. Enable Effective Containment Through Network Segmentation
Network segmentation limits attack spread by isolating systems and restricting lateral movement. When an incident occurs, segmentation helps contain affected assets and prevents attackers from easily reaching other parts of the environment. This reduces the overall impact of security incidents and supports faster recovery.
How to implement:
- Implement microsegmentation where possible to control communication between workloads.
- Design segmentation based on function and sensitivity.
- Combine segmentation with access controls and monitoring.
- Regularly review segmentation policies to ensure they align with current architecture and threat models.
Strengthening Your Incident Response Framework with Faddom
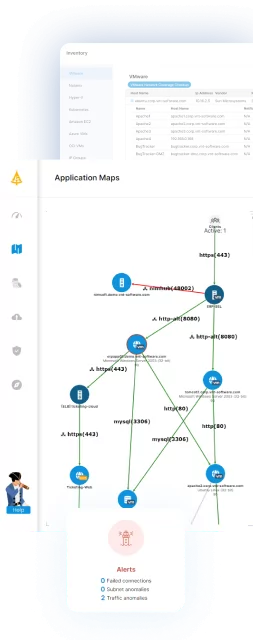
Every phase of an incident response framework — from preparation and identification through containment and recovery — depends on knowing exactly what exists in your environment and how it all connects.
Faddom is an agentless, non-intrusive platform that delivers real-time, complete visibility into network connections and dependencies, helping organizations strengthen their security posture and maintain compliance in minutes. By turning complex network activity into prioritized, actionable insight, Faddom gives security and IT teams the operational context they need to detect threats, contain incidents, and restore operations with confidence.
Key capabilities of Faddom:
- Real-time asset and dependency mapping: Automatically discovers and maps all on-prem servers, cloud instances, applications, and dependencies in under 60 minutes, agentless and without credentials — providing the complete, always-current inventory that effective preparation and identification require.
- Traffic anomaly detection with Lighthouse AI: A deep learning–based engine continuously learns the unique characteristics of your environment to surface unusual traffic behavior and potential threats, including DoS attacks, MITM attacks, DNS spoofing, port scanning, and data exfiltration, while minimizing alert noise.
- Risk prioritization and scoring: A unique scoring mechanism simplifies complex network activity into actionable insights, prioritizing risks by severity so teams address the most critical threats first.
- Microsegmentation planning and containment: Real-time visibility into ports, protocols, and traffic paths enables teams to plan micro-segmentation and reinforce security policies to limit lateral movement and contain incidents.
- Blind spot and shadow IT elimination: Identifies unmapped ports, misconfigured firewalls and access policies, lack of segmentation, and untracked shadow IT before they become entry points for attackers.
- CVE and lateral movement detection: Surfaces vulnerabilities, monitors north-south and east-west traffic, and detects lateral movement and unexpected connections across hybrid environments.
Learn more about Security Posture Management with Faddom and map your entire environment in under 60 minutes.