Data lies at the heart of everything you do as a business. From e-commerce to logistics and supply chains, in every industry around the world, the seamless online experiences customers have come to expect rely on how companies store, process, and distribute data and applications.
How organizations handle these functions has a massive impact. This means that, regardless of what industry they’re in, chances are data centers are a core component of their success.
There are many reasons for companies to rethink their data center architecture:
- Keeping up with new technology
- Adapting to changing business needs
- Optimizing costs
- Enhancing performance
- Other considerations, such as environmental impact, IT team’s needs, etc.
Whatever the reasons behind a data center implementation, modification, or upgrade, there are numerous factors to take into consideration to ensure the project succeeds.
This post will explore what goes into planning a data center, including all the elements of infrastructure required, the pros and cons of various models and architectures available today, and how to simplify the data center transformation journey. (On a related topic, learn more about IT documentation examples and best practices.)
Data Center Design Models
Before delving into the nitty-gritty of the required infrastructure, organizations first need to choose a model for their data center. This stage establishes the direction of the data center migration without committing to a particular concrete architecture.
Centralized
All computing and storage resources are located in a single physical location. This is best for organizations with a limited number of users or applications; it was common in the past because it’s the simplest to set up. However, the growing demand for high availability and the cost of maintaining large data centers has made this model less common today.
Converged
This model combines multiple IT infrastructure components (e.g., servers, storage, and networking) into a single, integrated chassis. A converged model is ideal for organizations that need to consolidate IT resources and have a mix of workloads with different performance and storage requirements.
Hyper-Converged
Here, the promise of convergence is taken one step further by bringing all components on board. This provides a highly scalable and modular infrastructure, along with greatly simplified IT operations via single-pane-of-glass management.
Cloud
A cloud data center provides virtualized data center infrastructure through on-demand access to online computing resources. This is ideal for organizations supporting large-scale or unpredictable workloads that require high availability and fault tolerance.
Edge
This model provides data centers closer to end users and devices. The edge approach is particularly useful for applications demanding low latency and high bandwidth, especially when data must be processed closer to the source, including content delivery networks and IoT.
Distributed
Using smaller data centers that are distributed geographically, a distributed model is especially useful for supporting local applications and data. Spreading computing resources out across multiple locations also improves resilience and reduces the impact of outages.
Data Center Architecture Components
Before planning the data center architecture, it’s essential for organizations to know what components they have to consider as well. In addition to the following elements, companies must also factor in power and cooling, network connectivity, security, and backups.
Compute
The following compute components are absolutely essential to the smooth operation of a data center.
Servers
Servers (e.g., web, application, file, database servers) store and process large amounts of data and run various applications.
In a physical data center, servers are usually mounted on racks and managed by an administrator. In a virtual data center, virtual servers are hosted by the cloud provider, which maintains the physical infrastructure. Virtual servers can be configured and managed to meet workload requirements, just as physical servers would be.
A reasonable degree of server redundancy is also important in a data center to ensure high availability and minimize downtime.
CPUs
CPUs vary greatly in terms of performance depending on their number of cores, clock speed, and cache size. Data centers generally require high-performance CPUs to support complex applications and workloads. Another consideration is energy efficiency, since higher power consumption leads to higher cooling costs.
CPUs are the workhorse of the data center, delivering better energy efficiency than GPUs for general-purpose tasks such as managing databases or running web servers.
GPUs
GPUs have become popular due to their high performance and greater energy efficiency for parallel processing. GPUs are commonly used in data centers for applications like machine learning, deep learning, and scientific computing. They’re ideal for complex mathematical problems; applications such as machine learning, where their parallel processing abilities can result in faster training times; or for processing video or image data.
Memory
Data center servers demand large amounts of memory for processing and storing large data sets. Factors to consider here include capacity, speed, and configuration.
For example, DDR4 is a fast, reliable memory type that might work for database servers handling large amounts of data and requiring rapid data access and processing. On the other hand, high-bandwidth memory such as HBM2 works best for complex scientific simulations or in high-end GPUs used for AI and ML.
Storage
Storage models vary greatly in terms of both their pricing and functionality. This means that an organization’s choice will make a big difference to cost and performance.
Hard Disk Drives (HDDs)
Hard disk drives (HDDs) have been a staple of data center storage for decades; they are reliable and durable. However, they are relatively slow compared to solid-state drives (SSDs) and are being gradually phased out in favor of SSDs because of this.
Although slower access times can be a drawback, HDDs are still common for data backup, archiving, and long-term storage, where speed is less critical.
Solid-State Drives (SSDs)
Solid-state drives have much faster read and write speeds and lower latency than HDDs. But they also come at a higher cost and have a shorter lifespan—plus, they’re more sensitive to power fluctuations. This makes them vulnerable to data loss and corruption, demanding rigorous redundancy and backups.
SSDs’ power-efficiency makes them a popular choice for high-performance applications that require fast access times and low latency; these include database servers, virtualization, and high-traffic web applications.
Network-Attached Storage (NAS)
Network-attached storage provides storage services to clients over the network. NAS systems use multiple hard drives or solid-state drives to provide redundant storage, which helps prevent data loss if a drive fails. In data centers, NAS is a staple for file sharing, backup, and archiving.
Because it’s simple to implement and maintain, NAS is often the go-to solution for small to medium-sized businesses that need centralized storage for users over the network.
Storage Area Networks (SANs)
A storage area network uses a dedicated network to connect storage devices to servers or clients. SANs provide high-speed storage access and can scale to support large amounts of data. Within the data center, SANs can drive high-performance, mission-critical applications that require high availability and reliability; these include enterprise databases, email servers, and virtualized environments.
More complex and expensive to implement and maintain, with specialized and dedicated hardware and software, SANs are generally used by large enterprises.
Network
In a physical data center, you are responsible for setting up and maintaining all of the components below. In a virtual data center, responsibility will vary depending on the cloud provider’s service agreement.
Routers
Routers connect networks and enable communication between them. In a data center, routers connect servers, storage devices, and other network components to the outside world. They help manage traffic and ensure that data is routed efficiently and securely.
Choosing routers with more memory and processing power can make your data center faster and more reliable.
Switches
Switches enable communication between devices on the same network, providing connectivity between servers, storage devices, and other network components. They work with routers, making sure data is transmitted efficiently and securely.
Higher-end switches with better quality of service (QoS) features offer better performance and reliability.
Firewalls
Firewalls use configured security rules to monitor and control all network traffic. In a data center, firewalls play a critical role in securing sensitive data and ensuring regulatory compliance.
Firewalls with more processing power and memory can provide deeper packet inspection and advanced security policies for incoming and outgoing traffic to keep your data center more secure.
Load Balancers
Load balancers distribute network traffic across multiple servers so that servers aren’t overloaded with traffic. In a data center, load balancers help optimize performance and ensure high availability. They keep applications accessible and responsive at all times.
High-end load balancers can deliver better performance, but this comes with a matching price tag.
Types of Data Center Architecture
Unlike the models and components explored above, the data center architecture describes how all the physical and logical components are connected to achieve the necessary functionality. The architecture determines how data will be moved, where data will be stored, and how it will be tested. Different architectures provide different levels of performance, scalability, reliability—and cost.
Many data center architectures use the analogy of leaves and spines—where leaves represent access switches at the edge of the network, while spines represent the core switches at the heart of the network. Another analogy in network layout is a “mesh.” Each device in a mesh can communicate with every other device, creating a decentralized network.
Apart from the possible architecture types, it’s also helpful to consider how the architecture handles “east-west” (between servers or devices within the data center) and “north-south” (between the data center and external networks or users) traffic. For example, container-based applications running on a microservices architecture demand high speed and reliability of east-west traffic, while a web server handling a high volume of users needs high speed and reliability for north-south traffic.
Mesh Network
A mesh network is non-hierarchical, using a distributed, peer-to-peer network of nodes to provide highly resilient and available infrastructure. All devices are interconnected, and data can be passed directly from any device to any other device. Because each node can communicate directly with others, this architecture provides fast and efficient data transfer.
A mesh network is generally the least expensive architecture model, with a simple topology that requires no specialized hardware.
- East-west: Higher speed, lower latency, but potentially lower fault tolerance (due to lack of dedicated paths)
- North-south: Higher latency
Three-Tier/Multi-Tier
This is by far the most common data center architecture today. It is simple, scalable, and can handle a wide range of workloads. Devices are grouped into three tiers: the presentation layer, the application layer, and the data layer. (In some variations, the three layers may break down into core, aggregation, and access, where core represents the spines and access represents the leaves.)
A three-tier architecture is generally more expensive than a mesh architecture, with a more complex topology and specialized hardware like load balancers.
- East-west: Lower speed, higher latency
- North-south: Lower latency, but potentially lower fault tolerance (due to single points of failure at each layer)
Mesh Point of Delivery (PoD)
This hybrid variation places computing resources closer to the network edge. Leaf switches are connected in a mesh topology, while spine switches are arranged hierarchically to provide scalability and resilience. Points of delivery (known as PoDs or pods) are connected by high-speed links and managed as a single pod. Overall, this reduces latency while improving performance and fault tolerance.
A mesh PoD architecture can be more expensive due to its overall complexity as well as the fact that it requires specialized equipment to handle routing intelligence.
- East-west: Higher speed, lower latency
- North-south: Higher latency and congestion
Super Spine Mesh
This is another hybrid architecture that uses multiple “super spines” to create a highly scalable and available infrastructure. By creating multiple redundant paths between points in the network, it provides some of the redundancy and scalability of a mesh network while maintaining the benefits of a multi-tier architecture, such as centralized management and traffic optimization. This architecture model is designed to handle large amounts of traffic and provide redundancy and failover capabilities.
A super spine mesh is typically the most expensive of the architectures covered here, as it is very complex and demands redundancy, scalability, and specialized equipment.
- East-west: Higher speed, lower latency, highly redundant and fault-tolerant
- North-south: Lower latency, fault-tolerant
Putting It All Together
Looking at the example of a medium-sized e-commerce company setting up a data center, let’s explore some of the choices they must make in terms of model, architecture, and components:
Data Center Model
This e-commerce company might choose a cloud-based data center model. They’ll get on-demand access to cloud computing resources with high scalability and easy application deployment and management.
For a startup company, the cloud-based model demands minimal investment. And as the company grows, their data center infrastructure can grow easily, although cloud expenses will obviously grow accordingly.
Data Center Architecture
This company might choose a mesh network architecture for its high levels of redundancy and resiliency. There is no single point of failure, ensuring high availability, which is essential to any e-commerce application.
Data Center Components
Although this company has chosen a virtualized architecture, they are still responsible for selecting components, such as processing power, memory, and storage capacity. They also need to consider factors such as geographic location, especially in relation to both their own and their customers’ locations.
How to Design a Data Center
In general, every data center transformation project goes through the following steps:
- Requirements: Define the business needs and objectives as well as the size, capacity, and power requirements for the data center. It is best to start with an inventory of all assets.
- Planning: Choose the appropriate data center model and architecture based on the business requirements and objectives; determine which components will be physical and which will be logical.
- Design: Select the physical (e.g., building, cooling, power) and logical (e.g., network, storage, compute) infrastructure to support all requirements, ensuring it is scalable and secure.
- Rollout: Begin with a detailed rollout plan that outlines the timeline, resources, and processes required to implement the design.
- Maintenance: Ensure that a comprehensive maintenance plan is in place that includes regular hardware and software updates, backups, security patches, and performance monitoring; this plan should be reassessed regularly.
For more information and a detailed, step-by-step overview of how to achieve a successful data center migration, see this post.
Faddom: Map Your Data Center Architecture Quickly
When data is the most crucial part of a business’s operations, they can’t afford to take data center architecture lightly. This is by no means a simple task and requires much thought and planning.
No matter what demands are placed on their data center, organizations need high agility for application and workload access, compute power, and security, all of which make the change more complex. There are so many choices that go into the model, components, and architecture—and it all begins with a solid understanding of an organization’s needs.
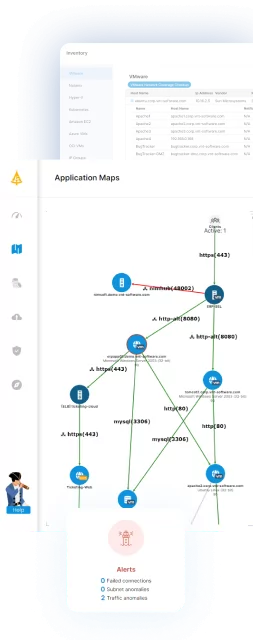
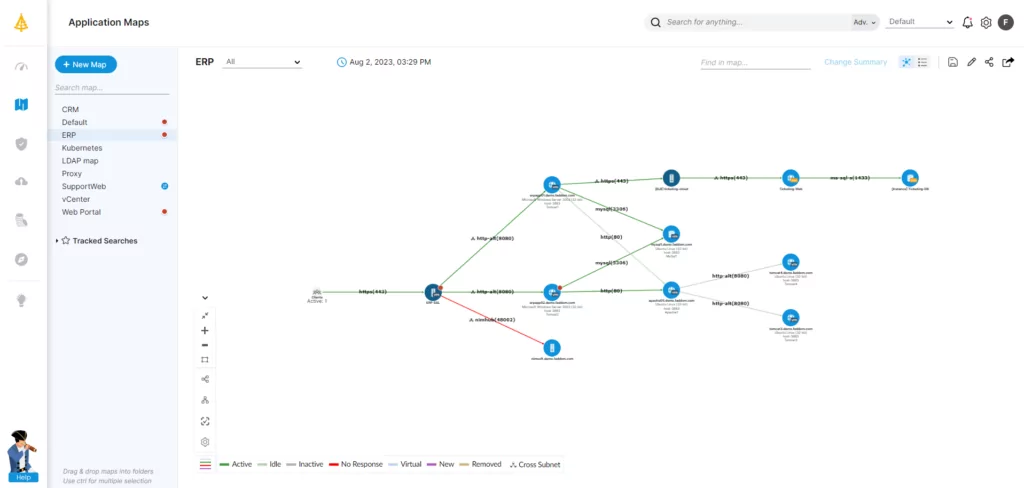
Luckily, there is a way to make the process far simpler: by starting with an application dependency mapping (ADM) tool like Faddom.
Faddom lets companies initiate their transformation from a position of strength: understanding the nature, configuration, and dependencies of all assets in the data center, the cloud, and at the edge. Faddom maps the entire hybrid IT environment, in the cloud and on-premises, in as little as one hour.
Organizations gain a comprehensive picture of the applications in use, their configurations, and their relationships with the underlying infrastructure—all of which are absolutely essential in understanding one’s data center architecture. Start a free trial today!