What Is AI Anomaly Detection?
AI anomaly detection refers to identifying data points, patterns, or events that deviate significantly from the norm using artificial intelligence techniques. These deviations, referred to as anomalies, often indicate critical issues such as system failures, fraud, or cyberattacks. Traditional methods struggle with large datasets, complex structures, and evolving patterns.
AI aims to resolve by leveraging machine learning and statistical models. AI models for anomaly detection use unsupervised or semi-supervised learning, depending on the availability of labeled training data. They identify anomalies by learning normal behavior patterns from historical data, enabling the detection of events that fall outside these patterns.
This process finds applications in cybersecurity, healthcare, and financial services, among others. AI-based solutions constantly improve as new data is collected, ensuring adaptive and accurate detection.
This is part of a series of articles about AI in cyber security
Table of Contents
ToggleKey Types of Anomalies
Single-Point Anomalies
Single-point anomalies are individual data points that differ significantly from the rest of the dataset. For example, a sudden spike in server traffic or an abnormally high bank transaction value can represent a single-point anomaly. These are often the simplest to detect because they require identifying a value outside the typical range. AI uses statistical thresholds or machine learning models to flag such irregularities efficiently.
However, accurately identifying single-point anomalies becomes challenging when noise or natural variability exists in the data. AI mitigates these issues by considering historical trends and relationships in the data, allowing for more accurate isolation of genuine anomalies.
Contextual Anomalies
Contextual anomalies occur when a data point is unusual only in a specific context, rather than appearing abnormal in isolation. For example, a temperature of 40°C might be typical in summer but highly unusual in winter, depending on geographic location. Context-aware anomaly detection analyzes both the data value and its context to distinguish between expected and anomalous behavior.
AI models designed for contextual anomaly detection often use recurrent neural networks or time-series analysis to incorporate temporal and environmental contextual information. This enables them to adapt to dynamic conditions and detect anomalies that would go unnoticed in simpler models. Such methods are used in weather forecasting, energy demand monitoring, and behavioral analytics.
Collective Anomalies
Collective anomalies refer to instances where a group of related data points collectively deviates from the normal pattern, even though individual points may not appear abnormal. For example, network traffic with unusual packet sequences can indicate a cyberattack, even if each packet is standard on its own. AI-driven techniques identify such anomalies by analyzing patterns and correlations in the data.
Identifying collective anomalies often involves clustering or deep-learning-based approaches to assess relationships among data points. These techniques are computationally intensive but effective in scenarios where understanding temporal or relational patterns is critical. Applications include fraud detection, where patterns in transaction sequences may reveal collusion or fraudulent behavior.
Traditional vs. AI-Based Anomaly Detection
Approach
Traditional anomaly detection methods often rely on statistical techniques and rule-based systems. These approaches include standard deviation analysis, z-scores, control charts, and predefined threshold rules. While effective for structured data with stable patterns, they struggle in dynamic environments and cannot easily adapt to new types of anomalies without manual reconfiguration.
AI-based methods leverage machine learning algorithms to learn patterns from data and automatically adjust to changes. Unlike static thresholds, AI models continuously update as new data becomes available, enabling detection of previously unseen or evolving anomalies. Techniques such as clustering, neural networks, and autoencoders allow for modeling complex, nonlinear relationships in data, which traditional methods typically overlook.
Scalability and Performance
Traditional techniques become less effective as dataset size and complexity increase. These methods may still serve niche scenarios with simple, well-understood data.
AI-based systems, particularly those utilizing deep learning, can handle large-scale, high-dimensional data and deliver results in real time. This makes them suitable for applications like fraud detection in financial systems, predictive maintenance in manufacturing, and intrusion detection in cybersecurity.
Key Machine Learning Algorithms for AI Anomaly Detection
Selecting the right machine learning algorithm is critical for effective anomaly detection. Different algorithms offer unique strengths depending on the data type, anomaly characteristics, and application needs. Here are some of the most widely used techniques in AI-based anomaly detection:
- Isolation Forest: This is designed for anomaly detection. It isolates anomalies instead of profiling normal data points. The algorithm creates random partitions of data and measures how many splits are required to isolate a point. Anomalies, being few and different, are isolated faster. This method is efficient for high-dimensional data and is well-suited for real-time applications.
- One-class SVM: One-class support vector machine learns a decision function for outlier detection in an unsupervised setting. It tries to capture the boundary around the normal data and classifies anything outside as anomalous. It works well with medium-sized datasets but can struggle with scalability and high-dimensional input unless carefully tuned.
- Autoencoders: These are neural networks that learn to compress and then reconstruct input data. Anomalies are detected by measuring reconstruction error—unusual data points will typically produce higher errors. Variational autoencoders (VAEs) and recurrent autoencoders extend this approach to handle probabilistic and sequential data respectively, making them useful for time-series anomaly detection.
- k-means clustering: k-means groups data into clusters based on similarity. Anomalies are detected by identifying points that are far from any cluster center. Though simple and easy to implement, it assumes spherical cluster shapes and can miss complex patterns unless combined with more advanced techniques.
- DBSCAN: Density-based spatial clustering of applications with noise (DBSCAN) identifies anomalies as points in low-density regions. It does not require the number of clusters to be specified in advance and can detect clusters of arbitrary shape. It’s effective in spatial data and applications where anomalies are expected to occur in isolated pockets.
- LSTM networks: Long short-term memory (LSTM) networks are a type of recurrent neural network (RNN) that excels in modeling time-series data. They are used for predicting future behavior based on past sequences. Anomalies are flagged when actual behavior deviates significantly from predicted behavior. LSTMs are commonly used in predictive maintenance and fraud detection.
- GANs: Generative adversarial networks (GANs) consist of a generator and a discriminator that compete during training. In anomaly detection, GANs can be trained to model normal data distributions. Data points that the discriminator identifies as fake are flagged as anomalies. While powerful, GANs require significant computational resources and careful tuning.

Lanir specializes in founding new tech companies for Enterprise Software: Assemble and nurture a great team, Early stage funding to growth late stage, One design partner to hundreds of enterprise customers, MVP to Enterprise grade product, Low level kernel engineering to AI/ML and BigData, One advisory board to a long list of shareholders and board members of the worlds largest VCs
Tips from the Expert
In my experience, here are tips that can help you better implement and sustain AI anomaly detection systems:
- Use hybrid detection models for layered sensitivity: Combine statistical, clustering, and deep learning methods to create multi-stage pipelines—e.g., first use isolation forests for coarse filtering, then autoencoders for fine-grained anomaly scoring. This improves precision and reduces false positives.
- Adopt concept drift detectors as first-class citizens: Integrate dedicated drift detection modules (like ADWIN, DDM) to monitor data distribution changes continuously. Trigger retraining or adaptation pipelines based on detected drift rather than static schedules.
- Leverage transfer learning across domains: If labeled anomaly data is scarce, reuse pre-trained models from similar domains (e.g., from IT operations to industrial control systems) and fine-tune them. This jumpstarts performance without needing large labeled datasets.
- Apply attention mechanisms in time-series models: Enhance LSTMs and Transformers with attention layers to highlight which past behaviors most influence current predictions, improving both detection accuracy and interpretability in sequential data.
- Create synthetic anomalies for balanced datasets: Generate realistic synthetic anomalies using simulation, GANs, or rule-based injectors to enrich training data. This helps improve supervised and semi-supervised model performance in imbalanced datasets.
Use Cases of AI in Anomaly Detection
Intrusion Detection
AI anomaly detection is a cornerstone of modern intrusion detection systems (IDS). Traditional IDS rely on predefined rules or signatures to detect threats, but these fail against novel or evolving attacks. AI-powered systems use machine learning to profile normal network behavior and identify deviations that may indicate intrusions, such as unusual login times, access patterns, or data transfers.
Commonly used techniques include unsupervised learning models like isolation forests and autoencoders that do not require labeled attack data. These models continuously learn from network traffic, adapting to changing usage patterns and reducing false positives. Real-time analysis enables the prompt identification of suspicious activities.
Learn more in our detailed guide to AI intrusion detection
Malware Detection
AI improves malware detection by identifying abnormal behavior patterns instead of relying solely on known signatures. Traditional antivirus software struggles with zero-day attacks and obfuscated malware, which evade static analysis. AI models, particularly those based on deep learning, analyze dynamic features such as file behavior, system calls, and execution traces to detect malicious activity.
Recurrent neural networks (RNNs) and convolutional neural networks (CNNs) are often used to model temporal sequences and detect subtle behavioral anomalies. These models can generalize from seen samples to detect new or mutated malware variants. AI-driven detection systems are integrated into endpoints and cloud environments to provide continuous protection.
Fraud Detection and Operational Optimization
AI anomaly detection is extensively used in financial systems for real-time fraud detection. It identifies anomalies in transaction patterns that could indicate fraudulent activity, such as irregular spending behavior, high-risk geographic access, or compromised account activity. Machine learning models learn from user behavior to establish baselines and flag deviations.
Techniques like clustering, autoencoders, and LSTMs allow detection of both individual suspicious actions and complex fraud schemes involving multiple coordinated transactions. Beyond fraud, AI anomaly detection aids in operational optimization by spotting irregularities in process performance, equipment behavior, or user activity.
Challenges in AI Anomaly Detection
Here are some of the main factors complicating the identification of anomalies.
Data Labeling Complexity
Many AI anomaly detection models require labeled data to train effectively, particularly in supervised learning contexts. However, acquiring labeled anomaly data is challenging due to the rarity and unpredictability of anomalies. Manual labeling is time-consuming and often impractical, especially in domains with large-scale or high-dimensional data.
False Positives
False positives—where normal behavior is incorrectly flagged as anomalous—can erode trust in AI systems and lead to alert fatigue. High false positive rates are especially problematic in real-time environments like cybersecurity or industrial monitoring, where each alert demands a response.
Scalability in Large Systems
As data volume and velocity increase, ensuring that anomaly detection systems scale efficiently becomes a major challenge. Traditional algorithms often falter under high-dimensional or streaming data. Real-time processing, required in use cases like network intrusion detection or IoT monitoring, adds further computational demands.
Ensuring Model Interpretability
AI models, particularly deep learning-based ones, are often criticized for their black-box nature. Lack of interpretability hinders trust and limits adoption in critical fields like finance and healthcare, where users need to understand why a decision was made.
5 Best Practices for Sustainable AI Anomaly Detection
Here are some of the ways that organizations can ensure consistent and reliable detection of anomalies using AI.
1. Define Business Objectives First
The success of AI anomaly detection initiatives hinges on clearly defined business objectives. These objectives should guide the choice of metrics, model complexity, data inputs, and operational constraints.
For example, a financial institution aiming to reduce transaction fraud may prioritize high recall to catch as many fraudulent events as possible, even at the cost of some false positives. In contrast, a manufacturing plant monitoring equipment health may emphasize precision to avoid costly downtime due to false alerts.
Defining objectives upfront prevents scope creep and helps teams decide on the right trade-offs—such as model explainability vs. accuracy or training time vs. real-time capability. It also simplifies decisions around alert thresholds, response protocols, and resource allocation.
2. Maintain High-Quality Data Pipelines
Anomaly detection models are only as good as the data they process. Dirty, delayed, or inconsistent data can cause significant degradation in model performance, resulting in increased false positives or missed anomalies. High-quality data pipelines ensure that input data is accurate, complete, timely, and consistent across sources.
This starts with data engineering practices: automated ingestion pipelines, schema validation, anomaly filtering, and time-synchronization for time-series data. Preprocessing steps such as normalization, missing value imputation, and outlier filtering should be implemented to maintain consistency.
Monitoring data pipelines in production is equally important. Systems should flag ingestion failures, schema changes, or sudden distribution shifts that could affect model predictions. Logging and observability tools help track data quality over time, while alerts notify engineers of issues before they affect outcomes.
3. Continually Retrain and Tune Models
Anomaly detection models must adapt to shifts in system behavior, user patterns, or external factors such as seasonal trends or market volatility. Without retraining, models become stale and their performance deteriorates, leading to an increase in missed anomalies or irrelevant alerts.
Retraining frequency depends on the domain and rate of data change. For dynamic environments like eCommerce or cybersecurity, daily or weekly retraining may be necessary. In more stable contexts like manufacturing or medical diagnostics, monthly or quarterly retraining may suffice.
Model performance should be tracked using relevant metrics—precision, recall, F1 score, AUC, and false positive rate—and compared over time. Drift detection algorithms can flag when model accuracy degrades due to distributional shifts, triggering retraining. Tuning includes adjusting hyperparameters, changing the feature set, or even selecting a different model architecture based on updated data characteristics.
4. Engage Domain Experts for Contextual Insights
Domain expertise is critical in AI anomaly detection because anomalies are often context-dependent. What appears to be an outlier to a model might be completely normal within operational context, and vice versa. Experts help define what constitutes an actionable anomaly and calibrate detection systems accordingly.
During model development, domain experts provide input on which features are meaningful, which data sources are trustworthy, and what types of anomalies matter most. They also help identify common false positives and guide the design of post-processing logic to filter them out.
During validation and testing, expert feedback helps interpret edge cases, validate alert thresholds, and evaluate whether anomalies are operationally significant. This human-in-the-loop approach improves model reliability. Post-deployment, engaging experts ensures that detected anomalies are reviewed, contextualized, and acted upon appropriately.
5. Implement Robust Alert Management
Anomaly detection is only useful if the resulting alerts drive timely and effective action. Without a reliable alert management system, teams may ignore alerts due to fatigue, or overreact to minor deviations, causing unnecessary disruption.
Effective alerting requires prioritization. Each anomaly should be scored based on severity, confidence level, and business impact. Integration with ticketing, incident management, or messaging systems (e.g., PagerDuty, Jira, Slack) ensures alerts are delivered to the right people in real time. Alert deduplication and suppression rules help prevent noise during recurring incidents.
Feedback from resolved alerts should be captured to improve the system. For example, labeling false positives or annotating alert resolutions helps refine models and post-processing rules. Dashboards and reporting tools should provide visibility into alert volume, types, resolution times, and model performance.
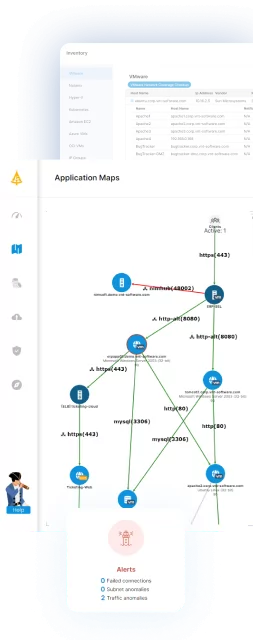
AI Anomaly Detection in Your Network with Faddom
As more organizations embrace AI to uncover hidden risks in their networks, Faddom’s new Lighthouse AI brings a fresh approach to anomaly detection. Designed to eliminate noise and surface only what matters, Lighthouse continuously analyzes server communications to detect abnormal behavior, such as traffic spikes, DNS anomalies, or suspicious access patterns, without manual thresholds or constant tuning.
By learning the normal rhythm of your environment, it flags deviations in real time and helps teams act faster with greater clarity. Faddom’s network topology mapping makes AI-powered detection practical, actionable, and privacy-conscious, giving IT and security teams the insight they need before issues become incidents.
If you want to see how this works in your own environment, book a personalized demo with one of our Faddom experts.